
JS引擎h2
我们知道,高级程序语言都是需要转成机器指令来执行的。
无独有偶,JS无论在浏览器中,还是在Node.js中,最终都是需要被CPU执行的。
但是CPU只认识自己的指令集,所以我们需要一个翻译器,也就是JS引擎将JS代码翻译成CPU认识的指令。
常见的JS引擎:V8(Google),SpiderMonkey(第一款),Chakra(微软),JavaScriptCore(苹果)
浏览器内核和JS引擎的关系
这里,我们以WebKit为例,WebKit是浏览器内核,而V8是JS引擎。
WebKit实际上由两部分组成:WebCore和JavaScriptCore。
- WebCore负责HTML的解析、布局、渲染等相关工作
- JavaSciprtCore负责解析、执行JS代码
JS三种编写方式h2
位置1:HMTL代码行内(不推荐)
<a href="#" onclick="alert('hello world')">点击</a><!-- <a href="javascript:alert('hello world')">点击</a> -->位置2:script标签中
<a class="google" href="#">点击</a><script> var googleElement = document.querySelector('.google') googleElement.onclick = function () { alert('谷歌一下') }</script>位置3:外部的script文件
var bingElement = document.querySelector('.bing')bingElement.onclick = function () { alert('必应一下')}<a class="bing" href="#">点击</a><script src="./js/bing.js"></script>基本注意事项:
- script标签一定是双标签形式,不允许写成单标签;
<script src="./js/bing.js" /> 错误
<script src="./js/bing.js"></script> 正确- 在外联式引用时,标签内代码无效,不要写
<script src="./js/bing.js">alert('hello world') // 这段代码会被无视</script>- 要注意加载顺序,作为HTML文档内容的一部分,js代码默认遵循HTML文档的加载顺序,即自上而下的加载顺序,推荐将js代码放在body的最后一行。
<body>
<!-- 会报错,因为按照顺序加载,bingElement为null -->
<script> var bingElement = document.querySelector('.bing') bingElement.onclick=function(){ alert('Bing一下') } </script>
<a class="bing" href="#">点击Bing</a>
</body>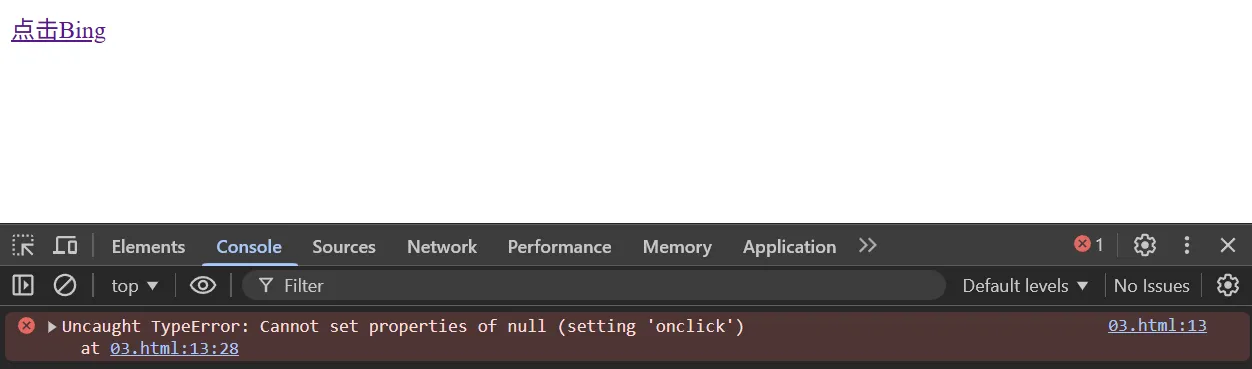
如果你非要写在前面,就必须使用回调函数,最常用的方式是利用window.onload事件。这相当于告诉浏览器:先把页面上的图片、标签都加载完,回头再调用在这个函数里的代码。
<body>
<script> window.onload=function(){ var bingElement = document.querySelector('.bing') bingElement.onclick=function(){ alert('Bing一下') } } </script>
<a class="bing" href="#">点击Bing</a>
</body>-
js代码严格区分大小写,HTML元素和CSS属性不区分大小写
-
在以前的代码中,
<script>标签中会使用type="text/javascript"属性来指定脚本类型,但在现代HTML5中,这个属性是可选的,默认就是JavaScript类型,因此可以省略。
noscript标签h2
当浏览器不支持JavaScript时, noscript标签中的内容就会显示。
比如我们在浏览器中禁用JavaScript
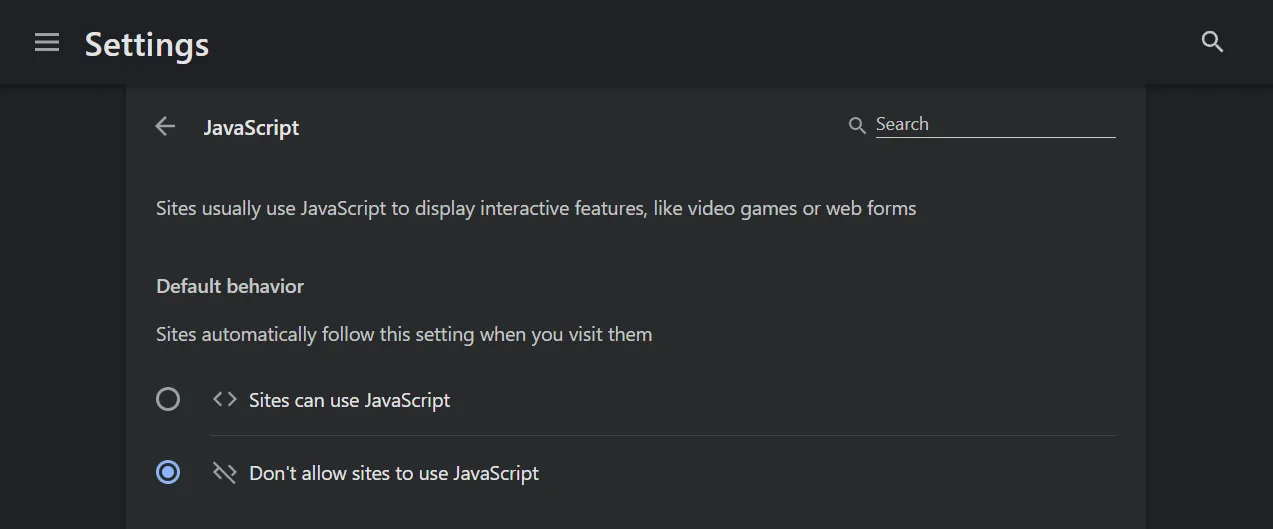
<noscript> 您的浏览器不支持JavaScript,请更换浏览器 </noscript><script> alert('hello world')</script>则只会显示noscript标签中的内容,反之,则只会执行script标签中的内容。
数据类型h2
JavaScript中的数据类型分为两大类:基本数据类型和引用数据类型。
基本数据类型包括:number、string、boolean
其中,number代表整数和浮点数
var age = 18var height = 1.75number可以有很多操作,除了四则运算还可以有自增和自减
除了常规的数字,还包括特殊数值,比如Infinity(无穷大),-Infinity(负无穷大),NaN(Not a Number,非数字),这些都属于number类型
var num1 = Infinityvar num2 = 1 / 0console.log(num1, num2) // Infinity Infinity
var max = Number.MAX_VALUEvar min = Number.MIN_VALUEconsole.log(max, min) // 1.7976931348623157e+308 5e-324注意:Number.MIN_VALUE为js中能表示的最接近0的正数
NaN代表一个计算错误,是一个错误操作所得到的结果,比如让字符串和一个数字相乘
var result = 3 * 'abc'console.log(result) // NaNisNaN()是一个全局函数,不是简单地检查它是不是 NaN,而是检查它尝试转换为数字后,是不是 NaN。
var result = 3 * 'abc'console.log(isNaN(result)) // trueconsole.log(isNaN('123')) // falseconsole.log(isNaN('123abc')) // true比如对于console.log(isNaN('123'))这个例子,isNaN拿到字符串'123'后,内部先尝试用Number()方法把它转换,发现123是一个合法的数字,所以“它是 NaN”这个命题为假
number类型还可以是不同进制的数
var num3 = 100var num4 = 0x100 // 16进制var num5 = 0b100 // 2进制var num6 = 0o100 // 8进制console.log(num3, num4, num5, num6) // 100 256 4 64字符串用于表示文本信息,引号用法可以是双引号、单引号和反引号
var name = 'felix'var address = 'mascot'var info = `name:${name}, address:${address}`console.log(name, address, info) // felix mascot name:felix, address:mascot和别的语言一样使用反斜杠进行转义。
var intro = 'felix is "top" man, in our \'engineering department\''console.log(intro) // felix is "top" man, in our 'engineering department'字符串里的常见属性和方法
length属性:获取字符串的长度
字符串拼接:可以使用+运算符拼接,但是+遇到像1+1+'3'这种情况就是'23'了,而我们希望拼接成113,那就得用到concat()
// 让空字符串作为“调用者”var result = ''.concat(1, 1, '3')console.log(result) // "113"注意:concat()方法返回的是一个新的字符串,原字符串不变
或者使用上面说到的模板字符串,这种最推荐,最现代,完全不用担心类型转换顺序,所见即所得
var n1 = 1var n2 = 1var str = '3'
// 也就是 `${变量}...`console.log(`${n1}${n2}${str}`) // "113"还有一种办法“强制转换”:在算式最前面加一个空字符串 "",利用 + 的隐式转换规则,强制把后面的都变成字符串处理。
// 只要开头是字符串,后面就全是字符串拼接console.log("" + 1 + 1 + '3') // "113"charAt()方法:从0开始,返回指定索引位置的字符,其实可以直接使用中括号访问(像数组一样)
var str = 'Hello'
// 传统写法console.log(str.charAt(1)) // 输出: "e"
// 现代写法(推荐)console.log(str[1]) // 输出: "e"indexOf(str)方法:查找子字符串第一次出现的位置,找到返回索引,找不到返回-1
如果有第二个参数,比如indexOf(str,2),那么就是从索引2开始找str
includes(str)方法:判断是否包含某个字符串,返回true或false
var msg = 'Hello World'console.log(msg.indexOf('o')) // 4console.log(msg.indexOf('x')) // -1
console.log(msg.includes('World')) // trueslice(start,end):提取字符串的一部分,包含start,不含end(左闭右开),如果不写end,则一直截取到最后
var str = 'Hello Python'
// 基础:左闭右开// 对应 Python: str[6:10]console.log(str.slice(6, 10)) // "Pyth" (含索引6,不含索引10)
// 负数:从后往前数// 对应 Python: str[-6:]console.log(str.slice(-6)) // "Python" (取最后6个字符)
// 掐头去尾// 对应 Python: str[1:-1]console.log(str.slice(1, -1)) // "ello Pytho" (去掉第一个和最后一个)
console.log(str.slice(6)) // "Python" (从6开始取到结束)substring(start, end)的特点,可以智能交换,如果start比end大,他会自动帮你把两个数字对调位置(slice则不会,会返回空字符串),但是他不认负数,它遇到任何负数,都会直接当成0处理
var str = 'Hello World'
// 1. 正常用法:和 slice 一模一样console.log(str.substring(1, 4)) // "ell"console.log(str.slice(1, 4)) // "ell"
// 2. 参数写反了(大数在前)// substring: 自动帮你换成 (1, 4),能正常截取console.log(str.substring(4, 1)) // "ell"// slice: 认为是无效范围,返回空console.log(str.slice(4, 1)) // "" (空字符串)
// 3. 遇到负数// substring: 把 -3 变成 0,相当于从头截取console.log(str.substring(-3)) // "Hello World"// slice: 真正理解“倒数第3个”console.log(str.slice(-3)) // "rld"substr这个方法是以前老代码里常用的,但现在不推荐使用(虽然浏览器还支持,但在标准中已被归类为“遗留特性”)。
它与substring最大的区别在于第二个参数:它是长度(个数),而不是结束索引。
var str = 'Hello World'
// 1. 核心区别:第二个参数是“我要截取几个字”// 从索引 2 开始,往后数 5 个字console.log(str.substr(2, 5)) // "llo W"
// 对比 slice (从索引2开始,到索引5结束)console.log(str.slice(2, 5)) // "llo"
// 2. start 可以是负数 (和 slice 一样倒着数)// 从倒数第 3 个开始,截取 2 个字console.log(str.substr(-3, 2)) // "rl"
// 从倒数第3个开始,截取 -1 个字(长度不能为负,视为0)console.log(str.substr(-3, -1)) // ""注意:substr 已被官方标记为Deprecated。在写新代码时,请永远优先使用slice。
toUpperCase()/toLowerCase():转大写/小写,常用于不区分大小写的搜索或比较
trim():去除字符串两端的空白字符(空格、换行),处理用户输入(比如表单用户名)时必用
var input = ' admin 'console.log(input.trim()) // "admin" (去除了左右空格)split(separator):根据分隔符,将字符串切成数组,这是字符串和数组转换的桥梁
var data = 'apple-banana-orange'var arr = data.split('-')console.log(arr) // ["apple", "banana", "orange"]如果有第二个参数n,意思是只保留前n个分割结果
var data = 'apple-banana-orange-pear'
// 第二个参数 2 表示:数组长度最大为 2// 也就是说,切出前两个后,剩下的直接丢弃!var arr = data.split('-', 2)
console.log(arr) // ["apple", "banana"]replace(old,new):替换匹配的字符串,默认只替换第一个匹配到的,如果想替换所有,需要用正则或者replaceAll
var str = '因为你喜欢苹果,所以我也喜欢苹果'
// 局限性:只替换了第一个“苹果”var result1 = str.replace('苹果', '香蕉')console.log(result1) // 因为你喜欢香蕉,所以我也喜欢苹果
// 方法一:使用正则 /.../gvar result2 = str.replace(/苹果/g, '香蕉')console.log(result2) // 因为你喜欢香蕉,所以我也喜欢香蕉
// 方法二:使用 replaceAllvar result3 = str.replaceAll('苹果', '香蕉')console.log(result3) // 因为你喜欢香蕉,所以我也喜欢香蕉注意:slice, substring, substr, trim, toUpperCase, replace, split 等,它们都不会修改原来的字符串变量,而是返回一个新的字符串。原因是在js中,string是基本数据类型,基本数据类型的一个核心特征就是不可变性,一旦一个字符串被创建出来,它就定型了,无法被修改。
所有看似修改了字符串的方法,实际上都在后台做了三件事:
- 复制一份原字符串的内容。
- 对副本进行操作。
- 返回一个新的值(新的字符串、数组或布尔值)。
boolean类型用于表示真假,在js中用的是true和false
undefined类型,如果变量没有被赋值,比如
var messageconsole.log(message) // undefined最好在变量定义的时候进行初始化,而不只是声明一个变量;
不要显式的将一个变量赋值为undefined,如果变量刚开始什么都没有,可以初始化为0、空字符串、null等值
console.log(message1) // undefinedvar message1 = 'hello world'这里之所以不报错而是输出undefined,是因为js的变量提升机制。
Object类型是一个特殊的类型,我们通常称之为引用类型或者复杂类型
相比其他的数据类型,也就是原始类型,因为它们的值只包含一个单独的内容(字符串、数字或其他)
之所以叫引用类型,是因为传递的是地址,如下
// --- 基本数据类型:传递的是值(互不影响) ---var a = 10var b = ab = 20console.log(a) // 10 (a 不变)
// --- 引用数据类型:传递的是地址(牵一发而动全身) ---var obj1 = { name: 'Felix' }var obj2 = obj1 // 这里给的不是对象本身,而是内存地址(钥匙)obj2.name = 'Jimmy'console.log(obj1.name) // "Jimmy" (obj1 也跟着变了!)Object往往可以表示一组数据,是其他数据的一个集合
在js中,我们可以使用花括号{}来表示一个对象
我们初始化一个对象时,可能不确定里面有哪些内容,会用{}定义,但是殊不知这样就不是一个空对象了
var book = {} // trueif (book) { console.log('book的逻辑代码执行')}// book的逻辑代码执行这是因为{}虽然里面没装东西,但这个盒子本身是存在的,在内存里占了位置。
所以当一个对象类型初始化时,不建议初始化为{},建议初始化为null
null类型不属于object类型,但typeof null会返回object,这是js历史遗留的bug,至今未修复
var objFelix = {}console.log(objFelix) // {}
var objJimmy = nullconsole.log(objJimmy) // null数组h2
数组静态方法:Array.isArray()返回的是一个布尔值,表示参数是否为数组,它可以弥补typeof运算符的不足
var arr = [1, 2, 3]console.log(typeof arr) // object
console.log(Array.isArray(arr)) // truepush和pop方法都会直接修改原数组
其中push()方法为末端添加,作用是在数组的末端添加一个或者多个元素,返回添加新元素后的数组长度
注意:不是返回数组本身
var arr = []
// 1. 添加单个元素var len = arr.push('UNSW')console.log(len) // 1
// 2. 再次添加arr.push('felix')
// 3. 一次添加多个arr.push(true, {})
console.log(arr) // ["UNSW", "felix", true, {…}]pop()方法为末端删除,作用为删除数组的最后一个元素,返回值是被删除的那个元素,如果数组已经空了,调用pop()会返回 undefined
var arr = ['UNSW', 'felix', 'WEB前端']
// 删除最后一个元素var deletedItem = arr.pop()
console.log(deletedItem) // "WEB前端" (取到了被删掉的值)console.log(arr) // ["UNSW", "felix"] (原数组变短了)push 进去了东西,数组变长了,所以返回长度 (Length)。
pop 拿出来了东西,手里拿着那个东西,所以返回拿出来的元素 (Element)。
头部操作:unshift(头部添加)和 shift(头部删除),逻辑和这一样,只是方向相反。
unshift用来在数组的开头添加一个或多个元素,返回添加新元素后的数组长度
var arr = ['UNSW']
// 在开头添加,原有的元素会自动往后顺延var len = arr.unshift('China')
console.log(len) // 2console.log(arr) // ["China", "UNSW"]
// 一次添加多个arr.unshift(1, 2) // 返回数组的长度 4console.log(arr) // [1, 2, "China", "UNSW"]shift用来删除数组的第一个元素,返回被删除的那个元素,这一点和pop一样
var arr = ['Apple', 'Banana', 'Orange']
// 删除第一个var firstItem = arr.shift()
console.log(firstItem) // "Apple"console.log(arr) // ["Banana", "Orange"]join就是上述字符串方法里split的逆过程,将数组转换成字符串
var str = 'hello world'var arr = str.split(' ')console.log(arr) // ["hello", "world"]console.log(arr.join('-')) // "hello-world"数组里的concat()和字符串里的concat()类似,用于拼接数组,返回一个新数组,原数组不变
参数类型灵活,数组参数会被”拍平”一层,非数组参数直接添加到新数组,可以任意组合混合参数,但是注意,嵌套数组不会完全拍平。
var arr = [1, 2]console.log(arr.concat(3, [4, 5], [[6, 7]])) // [1,2,3,4,5,[6,7]]// 注意:嵌套数组不会完全拍平
var arr = [1, 2]var result = arr.concat([3, [4, 5]])console.log(result) // [1,2,3,[4,5]] - 只展开一层
// 如果需要完全拍平,可以配合flat()console.log(arr.concat([3, [4, 5]]).flat()) // [1,2,3,4,5]在js中,字符串没有反转的方法,但是可以通过数组的reverse()方法实现
var str = 'hello world'var arr = str.split('')arr.reverse()console.log(arr.join('')) // "dlrow olleh"数组中的indexOf()方法和字符串中的indexOf()方法类似,用于查找某个元素在数组中第一次出现的索引位置,找不到返回-1
如果有第二个参数n,意思是从索引n开始查找
var arr = ['apple', 'banana', 'orange', 'banana']console.log(arr.indexOf('banana')) // 1console.log(arr.indexOf('pear')) // -1console.log(arr.indexOf('banana', 2)) // 3数组里也有slice()方法,它的作用是从原数组中提取一部分元素,组成一个新数组返回。不会修改原数组,而是返回一个新的浅拷贝数组。
左闭右开:参数 [start, end),包含 start,不包含 end。
var arr = ['a', 'b', 'c', 'd', 'e']
// 1. 基础用法:从索引 1 开始,切到索引 3 之前 (不包含 3)var res = arr.slice(1, 3)console.log(res) // ["b", "c"]console.log(arr) // ["a", "b", "c", "d", "e"] (原数组毫发无损)
// 2. 只有一个参数:从 start 一直切到最后console.log(arr.slice(2)) // ["c", "d", "e"]
// 3. 负数索引:表示倒数第几个// -1 代表最后一个,-2 代表倒数第二个console.log(arr.slice(-2)) // ["d", "e"] (提取最后两个)
// 4. 不传参数:常用于"浅拷贝"一个数组var copyArr = arr.slice()console.log(copyArr === arr) // false (内容一样,但地址不同,是新数组)数组中的splice()方法是数组中最强大的方法,可以理解为对数组进行外科手术。它可以对数组进行删除、插入、替换操作。
特点是直接修改原数组,返回被删除的元素组成的数组(如果没有删除,返回空数组)。
var arr = ['UNSW', 'felix', 'JS', 'React']
// 场景 1:删除 (Delete)// 从索引 1 开始,删除 2 个元素var deleted = arr.splice(1, 2)
console.log(deleted) // ["felix", "JS"] (返回被删掉的)console.log(arr) // ["UNSW", "React"] (原数组变了)
// 场景 2:插入 (Insert)// 重置一下数组arr = ['a', 'b', 'c']// 从索引 1 的位置开始,删除 0 个,插入 'x', 'y'arr.splice(1, 0, 'x', 'y')
console.log(arr) // ["a", "x", "y", "b", "c"]
// 场景 3:替换 (Replace)// 其实就是先删除,再插入arr = ['a', 'b', 'c']// 把 'b' 换成 'z' -> 从索引 1 开始,删掉 1 个,补上 'z'arr.splice(1, 1, 'z')
console.log(arr) // ["a", "z", "c"]函数h2
和其他高级语言一样,函数是一段可以复用的代码块,js中,可以用function关键字来定义一个函数
function命令声明的代码块,就是一个函数,如下格式
function 函数名(参数1, 参数2, ...) { // 函数体}函数声明会提升:js中,采用function命令声明函数时,整个函数会像变量声明一样,被提升到代码头部
add()
function add() { console.log(1 + 2)}但是另一种方式,函数表达式不会提升:
substract()
var substract = function () { console.log(2 - 1)}// 报错:substract is not a function原因很简单,这样声明实际执行顺序相当于:
var substract // 变量提升,substract 初始化为 undefined
substract()
substract = function () { console.log(2 - 1)}函数表达式是在代码被执行时被创建,并仅仅从那一刻起可用;而函数声明被定义之前,他就可以被调用。
对象h2
简单说,对象就是一组“键值对”的集合,是一种无序的复合数据集合
对象的每一个键名成为属性,对应的值称为属性值,可以是任何数据类型,如果属性值是一个函数,那么这个属性就称为方法
属性值还可以是一个对象,从而形成嵌套结构,调用起来就形成链式调用
var user = { name: 'jimmy', getName: function (name) { return name }, hommies: { bestFriend: 'william', goodFriend: 'tony', },}console.log(user.name) // jimmyconsole.log(user.getName('felix')) // felixconsole.log(user.hommies.bestFriend) // william作用域h2
作用域链:一层一层往外找
let a1 = 1 // 全局作用域console.log('a1', a1)function fn1() { let a2 = 10 // 函数作用域
console.log('a1', a1, 'a2', a2)
function fn2() { let a3 = 100 // 函数作用域
console.log('a1', a1, 'a2', a2, 'a3', a3) }
fn2()}fn1()
if (true) { let a4 = 1000 // 块级作用域 const a5 = 10000 // 块级作用域 var a6 = 10000 // 块级作用域 console.log('a4', a4, 'a5', a5, 'a6', a6)}
console.log('a4', a4) // 报错,a4未定义console.log('a5', a5) // 报错,a5未定义console.log('a6', a6) // 10000块级作用域的保护范围是 代码块,而函数作用域的保护范围是整个函数。由于 var 只识别函数边界,不识别块边界,所以它可以从代码块中’逃’到外部。
let和const都是 ES6中新增的用于声明变量的关键字,它们是用来取代旧的var关键字,并提供了块级作用域和更严格的变量声明方式。
let声明的变量,可以在声明所在的块级作用域内被访问,与var不同,它不能跨块访问,而且通常被认为是非提升的。
const声明的变量,表示常量,一旦赋值后就不能再修改。它也具有块级作用域,必须在声明时立即初始化,不能重新赋值,并且只能在声明它的块级作用域内访问。
const如果声明的是一个对象或数组,虽然不能重新赋值,但可以修改其内部的属性或元素。
举个例子:
const obj = { a: 1, b: 2 }console.log(obj === { a: 1, b: 2 }) // false,不同的对象引用// obj存储的是对象的地址,这个地址不能改变,但是地址指向的对象内容可以改变obj.a = 10 // OKdelete obj.b // OKconsole.log(obj) // { a: 10 }
obj = { c: 3 } // 报错,不能重新赋值数组也是如此:
const arr = [1, 2, 3]arr.push(4) // OKarr[0] = 10 // OKarr.pop() // OKconsole.log(arr) // [10, 2, 3]arr = [4, 5, 6] // 报错,不能重新赋值在实际中,比如配置对象
const config = { apiUrl: 'https://api.happyfelix.top', timeout: 5000,}
if (process.env.NODE_ENV === 'production') { config.apiUrl = 'https://api.happyfelix.top/prod' // OK config.debug = true // OK}
config = {} // 报错,不能重新赋值函数补充h2
函数式编程:函数作为一等公民
- 可以被赋值给变量(函数表达式写法)
- 可以让函数在变量之间来回传递
- 也可以作为另外一个函数的参数
- 还可以作为另一个函数的返回值
- 也可以存储在别的数据结构中,这一点刚才我们已经见识到了,比如存在数组、对象中
// 可以被赋值给变量var fn1 = function () { console.log('hello world')}
// 在变量之间来回传递var fn2 = fn1fn2()
// 作为另外一个函数的参数function bar(func) { console.log('func:', func)}
bar(fn1)
// 作为另一个函数的返回值function sayHello(name) { function greet() { return 'Hello, ' + name } return greet}
var greetFunc = sayHello('Felix')console.log(greetFunc()) // Hello, Felix在函数作为参数传递时需要注意,不要传递执行的函数结果,而是传递函数本身
function foo(fn) {}
function bar() { console.log('hello world')}
foo(bar()) // 错误,bar()执行结果是undefined,所以foo()的参数是undefinedfoo(bar) // 正确,传递的是函数本身回调函数h2
回调函数是一种常见的函数式编程概念,它允许函数在某个事件发生时执行。
function foo(callback) { console.log('foo函数开始执行') callback() console.log('foo函数执行完毕')}
function bar() { console.log('bar函数被调用')}
foo(bar)有何实际用处?
// 模拟网络请求,2秒后才回来function request(url, callback) { console.log('1. 发起请求...') // 使用 setTimeout 模拟网络延迟 setTimeout(() => { var result = '服务器返回的数据' callback(result) // 数据到了才通知你 }, 2000)}
function handleRequest(result) { console.log('请求完成,处理result', result)}
request('https://api...', handleRequest)console.log('2. 不用等结果,可以继续做其他事')JavaScript 是单线程的,假设request函数需要话很长时间拿到结果,比如说从服务器上下载一个大文件,或者读取数据库,如果不用回调模式,程序就会停在那里傻等。
回调函数允许我们在等待结果的同时,继续执行其他代码,当结果准备好时,再通过回调函数通知我们。
实际上,回调函数可以写成匿名函数的样子:
request('https//api...', function (result) { console.log('请求完成,处理result', result)})现代写法,我们通常把匿名函数写得更简洁,使用箭头函数的语法糖:
request('https//api...', (result) => { console.log('请求完成,处理result', result)})像request这种可以接受另外一个函数作为传入的参数的函数,我们称之为高阶函数(Higher-Order Function)。
高阶函数必须至少满足两个条件之一:
- 接受一个或多个函数作为输入
- 输出一个函数
匿名函数的理解:如果在传入一个函数时,我们没有指定这个函数的名词称或者通过函数表达式指定函数对应的变量,那么这个函数称之为匿名函数。
常用的高阶函数h2
数组的map、filter、reduce方法,都是非常常用的高阶函数。
map:进多少个,出多少个。map方法会遍历数组的每一个元素,并返回一个新的数组,这个数组的元素是原始数组元素经过处理后的结果。
// 比如说给prices数组里的每一个元素打8折const prices = [100, 200, 300]
// item 代表数组里的每一项const newPrices = prices.map(function (item) { return item * 0.8})
// 也可以写成箭头函数// const newPrices = prices.map(item => {// return item * 0.8// })filter:进多少个,出多少个。按条件筛选数组元素,返回包含所有通过项的新数组。
// 比如说 筛选出偶数const nums = [1, 2, 3, 4, 5, 6]
const evens = nums.filter((item) => { return item % 2 === 0})reduce:reduce方法会遍历数组的每一个元素,并返回一个结果。它把数组里的一堆东西,通过某种方式计算,最后变成一个东西(比如一个总数、一个对象)。
接受两个参数:callback和initialValue,其中
- 回调函数(pre,current)中,pre是上一次计算的结果,current是当前遍历到的值;
- 初始值是从什么值开始算
// 比如说 计算购物车里的所有商品的总价const nums = [10, 20, 30, 40]
// pre: 上一次累加的结果// cur: 当前遍历到的值// 0: 初始值,表示从0开始累加const total = nums.reduce((pre, cur) => { return pre + cur}, 0)// 计算过程:0+10 -> 10+20 -> 30+30 -> 60+40 -> 100立即执行函数h2
Immediately-Invoked Function Expression,顾名思义,一个函数被定义完后立即被执行
- 第一部分是定义了一个匿名函数,这个函数有自己独立的作用域
- 第二部分是后面的
(),表示这个函数被执行了
// function test() {// console.log('test this')// }// test()// 立即执行函数;(function () { console.log('test this immediately')})()这就等于定义了一个函数,然后立即执行它。
// 传入参数;(function (name) { console.log('hello', name)})('Felix')
// 同样也可以有返回值var result = (function (name) { return 'yours ' + name})('felix')console.log(result) // yours felix立即执行函数的产生有什么意义呢?立即执行函数和普通的代码有什么区别?
立即执行函数里的变量有自己独立的作用域,外部无法直接访问。通常情况下,它执行完就会销毁;但在涉及‘闭包’(比如绑定事件监听)时,它的作用域会被保留在内存中,不会被立即销毁,从而实现了数据的保存。
下面这段代码,如果用正常的匿名函数绑定每个按钮的点击事件,那么点击按钮时,i的值都是5,因为定义在for循环里var定义的i是没有自己的块级作用域的,等于是一个全局变量。
<button class="btn">btn1</button><button class="btn">btn2</button><button class="btn">btn3</button><button class="btn">btn4</button><button class="btn">btn5</button>
<script>
var btns = document.querySelectorAll('.btn');
for (var i = 0; i < btns.length; i++) { btns[i].onclick = function () { console.log(`btn${i + 1}`) // btn6 } }
console.log(i) // 5
</script>所以如果想解决这个问题,除了可以使用ES6的let代替var,还可以使用立即执行函数:
<script> var btns = document.querySelectorAll('.btn');
for(var i=0;i<btns.length;i++){ (function(input){ btns[input].onclick = function () { console.log(`btn${input + 1}`) } })(i) } console.log(i)</script>Solution “立即执行函数 + 闭包”:为每个按钮创建独立的词法环境,从而捕获循环中每个迭代的当前值。
创建独立作用域:每次循环迭代时,立即执行函数被调用,并接收当前 i 的值作为参数,比如input,这个参数input成为该立即执行函数内部作用域的局部变量。
闭包的形成:在立即执行函数内部,我们为按钮的 onclick 事件绑定了一个匿名函数。这个匿名函数引用了外部变量 input,因此形成了一个闭包 —— 即使立即执行函数执行完毕,其内部变量 input 依然被匿名函数保留在内存中。
值的捕获:由于每次迭代都会创建一个新的立即执行函数作用域,每个匿名函数都捕获了对应迭代时 input 的当前值。例如:
- 第一次迭代:input=0,第一个按钮的点击函数捕获 input=0
- 第二次迭代:input=1,第二个按钮的点击函数捕获 input=1
事件触发时的正确访问:当用户点击某个按钮时,对应的匿名函数被执行。由于闭包机制,函数能够访问它创建时捕获的 input 值,例如,点击第一个按钮时,函数访问的是 input=0
对象补充h2
遍历对象h3
for(var key in obj):用于遍历对象的可枚举属性,乍一看很像python的字典,但其实不一样。如果不加约束,会遍历原型链上的可枚举属性
for (var key in obj) { // 判断对象自身属性,否则会遍历原型链 if (obj.hasOwnProperty(key)) { var value = obj[key] console.log(key, value) }}for(var i = 0 ; i < Object.keys(obj).length; i++):使用索引遍历对象属性
var keys = Object.keys(obj)for (var i = 0; i < keys.length; i++) { var key = keys[i] var value = obj[key] console.log(key, value)}for(var key of Object.keys(obj)):由于Object.keys(obj)输出是一个数组,所以可以使用for ... of遍历
var keys = Object.keys(obj)// ES6for (var key of keys) { // 注意:这里遍历的是数组,不是对象 console.log(key, obj[key])}使用forEach,函数式编程:
Object.keys(obj).forEach(function (key) { console.log(key, obj[key])})引用类型h3
两个对象比较
var obj1 = {}var obj2 = {}
console.log(obj1 === obj2) // falsevar obj1 = {}
Heap:辟一块新的空间存放一个空对象,假设地址是 0x100。
Stack:变量 obj1 存储的是地址 0x100。
var obj2 = {}
Heap:再次开辟一块全新的空间存放另一个空对象,假设地址是 0x200。
Stack:变量 obj2 存储的是地址 0x200。
console.log(obj1 === obj2)
js引擎实际上是在问:0x100等于0x200吗?当然是false。
引用传递,但是函数中创建了一个新对象,没有对传入对象进行修改
function foo(a) { a = { name: 'felix', }}
var obj = { name: 'obj',}
foo(obj)console.log(obj) // {name: "obj"}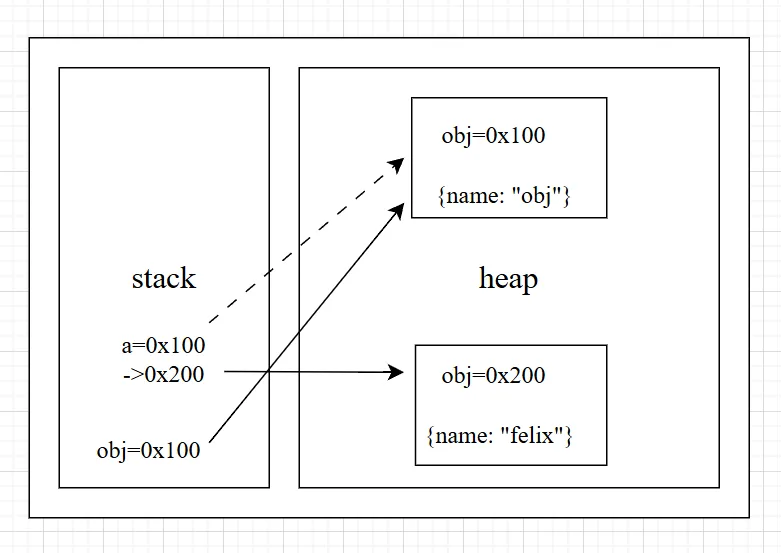
在堆内存地址0x100创了一个对象{name:"obj"},在栈中,变量obj保存了这个地址0x100,obj指向了0x100
foo(obj)调用函数,形参a被创建,它接受了obj传进来的值0x100,所以此时a也指向了0x100
函数内部,a = { name: 'felix' },一个新的对象{ name: 'felix' }在堆内存中被创建,地址假设是0x200,改变了a的指向。此时,a指向0x200,断开了与前任的联系。
外部的obj依然安安静静地指着0x100,因为它从未被修改过。
引用传递,但是对传入的对象进行修改
function foo(a) { a.name = 'felix'}
var obj = { name: 'obj',}
foo(obj)console.log(obj) // {name: "felix"}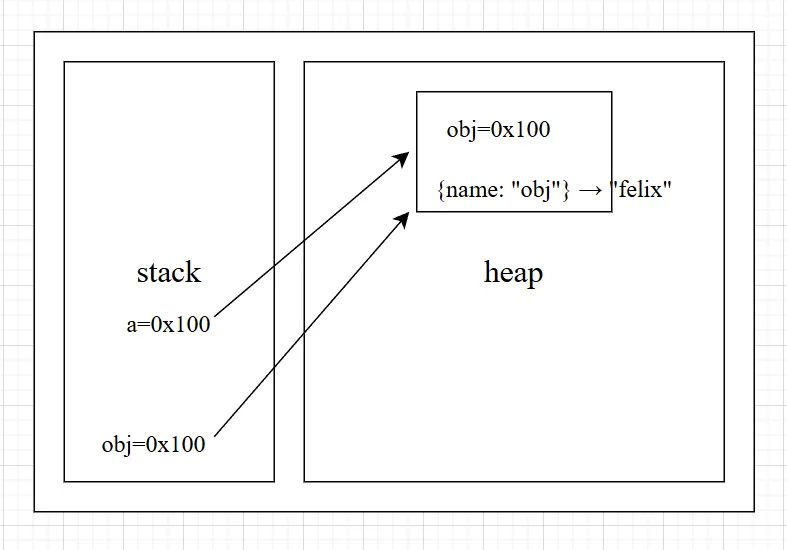
和上一段代码不同的是,执行 a.name = 'felix',顺着 a 手里的地址 0x100 找到堆里的那个对象,然后修改它的 name 属性。因为 obj 手里拿的地址也是 0x100,当它去查看那个对象时,看到的自然就是已经被修改过的内容。
函数的this指向h2
如果普通的函数被默认调用,那么this指向的就是window
function foo(name, age) { console.log(arguments) console.log(this)}foo('felix', 18)// [ 'felix', 18 ]// Window { ... }如果函数被一个对象引用并且调用它,那么this会指向这个对象
var obj = { name: 'felix', foo: function () { console.log(obj) console.log(this) console.log(this === obj) },}obj.foo() // 被对象引用并调用// { name: 'felix', foo: [Function: foo] }// { name: 'felix', foo: [Function: foo] }// true
var fn = obj.foofn() // 被函数默认调用// window函数被对象引用调用,this指向对象,但是对象被函数默认调用,this指向window
this有何作用呢?
如果没有this,而是直接写死对象的名字。
var info = { name: 'felix', running: function () { // 直接写死了变量名 info console.log(info.name + ' is running') },}
var p2 = info // 把对象赋值给新变量 p2info = null // 销毁原来的变量引用
// 报错!因为函数内部还在找 "info",但 info 已经没了p2.running() // Uncaught TypeError: Cannot read property 'name' of null缺点: 函数和变量名 info 强耦合绑死了。一旦改了变量名,或者想把这个函数给别的对象用,代码就挂了。
使用this之后,函数不再关心它被放在哪个变量里,它只关心谁在调用它。
我们可以定义一个通用的函数,然后让不同的对象去使用它:
// 1. 定义一个通用的逻辑function commonRunning() { // this 就像一个占位符,谁调用我,我就指向谁 console.log(this.name + ' is running')}
// 2. 创建两个不同的对象var person1 = { name: 'Felix', run: commonRunning, // 引用同一个函数}
var person2 = { name: 'Eric', run: commonRunning, // 引用同一个函数}
// 3. 同一个函数,表现出不同的行为person1.run() // 输出: Felix is runningperson2.run() // 输出: Eric is running初始全局对象windowh3
浏览器中,存在一个全局对象window,这个对象就是全局作用域,所有全局变量和函数都挂载在window对象上。
作用有哪些?首先是查找变量时,最终会找到window头上;其次,可以将浏览器全局提供给我们的变量、函数、对象,放在window对象上面;
注意,var定义的变量,会挂载在window对象上,而let、const定义的变量,不会挂载在window对象上。
引出工厂模式h2
如果要在开发中创建一系列的相似的对象,我们该如何操作呢?
比如在游戏中创建一系列英雄,他们具备的特性是相似的,比如都有名字、技能、价格,但是具体值又不同。
一种办法是我们创建一系列对象,挨个创建对象,但是这样效率很低,大量重复代码。
我们是否有可以批量创建对象,但是又让它们的属性不一样的呢?
有一种最基本的想法就是使用循环来创建对象
// 原始思路:for循环for (var i = 0; i < 3; i++) { var hero = { name: 'king arthur', age: 18, running: function () {}, }}但是这样创建,等于白忙活一场,循环结束后,我们手里只有最后一次循环创建的那一个对象,前几次循环创建的对象都丢失了,纯属浪费CPU资源;
把它们装进数组似乎可以解决这个问题:
var heros = []for (var i = 0; i < 3; i++) { var hero = { name: 'king arthur', age: 18, running: function () { console.log(this.name + ' is running') }, } heros.push(hero) // 把刚创建好的对象压入数组}console.log(heros) // 这样就能得到三个对象了但是我们的对象属性都是写死的,最终得到的是3个一模一样的对象。通常我们用循环是为了处理不同的数据,而不是为了复制3个完全一样的人。
为了创建不同的英雄,工厂模式似乎是一个更好的选择:
// 工厂模式function createHero(name, age) { var hero = { name: name, age: age, running: function () { console.log(this.name + ' is running') }, } return hero}
// 也可以这样创建对象// function createHero(name, age) {// var hero = {}// hero.name = name// hero.age = age// hero.running = function () {// console.log(this.name + ' is running')// }// return hero// }
var hero1 = createHero('king arthur', 43)var hero2 = createHero('merlin', 999)var hero3 = createHero('lancelot', 45)所谓工厂模式Factory Pattern,在js中,指的就是用一个函数把创建对象的细节封装起来,每次调用都返回一个新的对象。
从工厂模式到构造函数h2
构造函数是一种特殊的函数,通过 new 关键字来调用,构造函数会自动将 this 指向创建的对象。
如果一个函数被使用 new 操作符调用了,那么它会执行如下操作:
-
在内存中创建一个新的对象(空对象)
-
这个对象内部的
[[Prototype]]指向构造函数的prototype属性 -
构造函数内部的
this绑定到新创建的对象 -
执行函数的内部代码
-
如果构造函数没有返回非空对象,则返回创建出来的新对象
function createHero(name, age) { this.name = name this.age = age this.running = function () { console.log(this.name + ' is running') } // return this // 这一步可以省了,因为构造函数会自动返回this}
var hero1 = new createHero('king arthur', 43)为什么叫构造函数constructor,构造函数也叫构造器,通常我们在创建对象时会调用的函数,在其他面向对象的编程语言中,构造函数是存在于类中的一个方法,称之为构造方法;
但是js中有点不太一样,构造函数扮演了其它语言中类的角色(把它看成类也好理解)。
比如系统默认给我们提供的Date就是一个构造函数,但也可以看成是一个类,在ES6之前,我们通过function来声明一个构造函数(类),之后通过new关键字来对其进行调用;在ES6之后,js可以像别的语言一样,通过class来声明一个类。
函数本质就是对象h3
js中,函数其实就是一种特殊的对象(Callable Object,可调用的对象)。
可以像操作普通的对象一样操作函数,这在其他语言(如Java、C++)中都是不可想象的:
function foo() {}
// 给函数加属性(就像给对象加属性一样)foo.age = 18foo.myDescription = 'I am a function, but i am also an object'// 甚至把它当成参数传递console.log(foo.age)所以,所有的函数都是对象,但只有具备“特定能力”的函数才能当成构造函数。
构造函数等于类h3
在ES6之前,js没有class关键字,那时候,构造函数就是类。
即使到了现在,ES6引入了class写法,它本质上只是语法糖,底层的逻辑依然是刚才讨论的构造函数
class Hero { constructor(name, age) { this.name = name this.age = age } running() { console.log(this.name + ' is running') }}
var hero1 = new Hero('king arthur', 43)模式切换开关 new关键字h3
JavaScript 的函数内部有两个隐藏的插槽(Internal Slots):
[[Call]]:当你写 foo() 时,引擎激活这个插槽,单纯运行代码。
[[Construct]]:当你写 new foo() 时,引擎激活这个插槽,执行“创建对象、绑定 this、返回对象”那套流程。
所以,并不是函数变成了类,而是 new 关键字强行激活了函数内部的“工厂模式”。
只有一种函数贝能被newh3
虽然函数是对象,但不是所有函数都有“模具功能”([[Construct]] 插槽)。
箭头函数是个特例:
var foo = () => { console.log('I am an arrow function')}
var obj = new foo() // 报错!TypeError: foo is not a constructor原因: 箭头函数设计之初就是为了轻量级计算,它被阉割了 [[Construct]] 能力,也没有 prototype 属性,所以它永远成不了“类”。
包装类h2
原始类型(Primitive Types)本身确实没有属性,也没有方法。 它们在内存中仅仅是一个单纯的值(比如栈里的一个 123),不是对象。
那为什么 "123".length 能跑通?
看似悖论,但我们把这个过程慢放来看,以下代码为例:
var str = 'hello'var len = str.lengthjs引擎在读取 str.length,偷偷做了三件事:
- 包装:引擎发现你想调用属性,于是它瞬间用 String 构造函数创建了一个临时的对象实例。
var _temp = new String('hello')- 访问:它在这个临时对象上调用
.length属性,拿到了值 5。
var len = _temp.length- 销毁:任务完成,这个临时对象立即被销毁。
_temp = null为了证明这个“临时替身”的存在,我们可以做一个实验:试图给一个字符串加属性。
var name = 'felix'
// 1. 试图给原始类型加个属性name.age = 18// 过程:// -> 创建临时对象 temp1// -> temp1.age = 18// -> 销毁 temp1 (刚才赋的值随之灰飞烟灭)
// 2. 打印看看console.log(name.age) // undefined// 过程:// -> 创建全新的临时对象 temp2// -> 读取 temp2.age (新对象当然没有这个属性)// -> 销毁 temp2如果 name 真的是一个对象,name.age 应该能保存下来。 正是因为每次访问都会创建一个全新的、临时的包装类对象,所以第一行代码保存的数据,第二行根本拿不到。
原始类型补充h2
Number类h3
我们刚才说了,原始类型本身没有属性和方法。但是可以因为引擎会自动创建临时对象,所以可以给原始类型添加属性。
Number里有很多常用的类方法,比如.tofixed()、toString()、parserInt()、parseFloat()
var num = 123.321console.log(num.toFixed(2)) // 123.32console.log(num.toString(), typeof num.toString()) // 123 "string"// 进制准换,顺便变成字符串console.log(num.toString(2), typeof num.toString(2)) // 1111011 "string"
var str = 'hello'console.log(Number.parserInt(str)) // NaN
var num = '123.321'console.log(Number.parseFloat(num), typeof Number.parseFloat(num)) // 123.321. "number"// 不加 Number. 也可以console.log(parseFloat(num)) // 123.321parseInt 和 parseFloat 是全局函数(直属于 window),为了模块化,ES6把它们挂载到了Number上(即 Number.parseInt)。
为什么有的函数用
.,有的用Class.?
这取决于这个方法是为了操作自己还是为了提供工具。
实例方法 (Instance Methods),也就是我自己的技能,特点是必须由对象实例(具体的num或者str)来调用。num.toFixed(2) num 是具体的实例,它知道自己是 123.321,所以它能处理自己。
静态方法 (Static Methods) / 全局工具,公用的工具箱,特点是直接由类名(Number)调用,不需要实例化。Number.parseInt("123") 这里不需要一个具体的数字作为主语。相反,你是把字符串作为参数传进去,让工具去处理它。
Math对象h3
Math在上文中也提到过,是JavaScript中一个内置对象,拥有一些数学常数属性和数学函数方法。
和Number、String不同,Math不是构造函数,它不能被new。你不能创建一个Math实例(new Math()会报错)。它是单例对象,js引擎启动时,就已经把这个工具箱造好了放在那里。它里面的所有属性和方法,都直接通过Math.xxx调用,全是静态方法。
console.log(typeof Math) // "object" (注意:Number 是 "function")String类h3
String类和Number类一样,也是一个构造函数(类),可以用new来创建实例(虽然我们平时很少这么做)。
// 1. Math 不能 new (报错)// var m = new Math(); // Uncaught TypeError: Math is not a constructor
// 2. String 可以 new (成功)var str = 'hello'console.log(typeof str) // "string"
var strObj = new String('hello')console.log(strObj) // [String: 'hello'] <-- 看!这是一个对象console.log(typeof strObj) // "object" <-- 它的类型是对象,不是字符串字面量写法创建字符串还是保持着原始值,轻量级,存在于栈中。
用new创建对象,重量级,存在于堆中。
var s1 = 'hello'var s2 = new String('hello')
console.log(s1 === s2) // false (类型都不一样)
var emptyStr = ''var emptyObj = new String('') // 创建一个内容为空的"对象"
if (emptyStr) { console.log('A') // 不会打印 (空字符串是 false)}
if (emptyObj) { console.log('B') // 会打印!! (任何对象都是 true,哪怕它是空的)}小结h3
Math:确实不能new,它是纯工具。
String/Number/Boolean:都能new。它们既是工具(提供静态方法如Number.parseInt),也是类(能创建包装对象)。
只是在绝大多数情况下,不要手动new它们。这会把简单的原始值变成复杂的对象,引发各种bug。
数组中的高阶函数h2
我们现在有一个需求:有一个数组,数组中的每个元素都是一个对象,对象有name和age两个属性。我们如何找到数组中,姓名为”king authur”的元素?
var heros = [ { name: 'King authur', age: 45 }, { name: 'Merlin', age: 999 }, { name: 'Lancelot', age: 43 },]普通做法:遍历数组
for (var i = 0; i < arr.length; i++) { var item = heros[i] if (item.name === 'King authur') { console.log(item) break }}find方法h3
var kingAuthur = heros.find(function (item) { return item.name === 'King authur'})
console.log(kingAuthur)find方法会遍历数组,对数组中的每一个元素执行我们自己写的回调函数。
如果回调函数返回true:说明找到了,find会立即停止遍历(不再看后面的元素),并直接返回当前这个元素;如果回调函数返回 false:说明不是这个,继续看下一个。
如果遍历完所有元素都没返回true:说明没找到,最终返回undefined。
forEach方法h3
forEach方法 和 find方法很像,但是它没有返回值,作用是遍历数组,对数组中的每一个元素执行我们自己写的回调函数。
这个回调函数被调用时将传入以下参数:当前元素、正在处理的当前元素的索引、调用forEach的数组本身。
我们先来自己实现以下:
var arr = [1, 2, 3, 4, 5]function myForEach(fn) { for (var i = 0; i < arr.length; i++) { fn(arr[i], i, arr) }}
myForEach(function (item, index, array) { console.log(item, index, array)})
// 这样也行,传入两个参数// function myForEach(fn,array){// for(var i=0;i<array.length;i++){// fn(array[i],i,array)// }// }// myForEach(function (item, index, array) {// console.log(item, index, array)// }, arr)另一个版本,也是更接近于forEach的实现。数组就是一种特殊的对象,可以把myForEach挂载到数组对象上。
var arr = [1, 2, 3, 4, 5]arr.myForEach = function (fn) { for (var i = 0; i < this.length; i++) { fn(this[i], i, this) }}
arr.myForEach(function (item, index, array) { console.log(item, index, array)})其实还有一个版本,因为如果我们写了一个myForEach方法并把它挂载到一个数组对象上,那么如果这时候还有别的数组对象也像使用还得重新定义,复用率很低。我们可以挂载到Array的原型上:
Array.prototype.myForEach = function (fn) { for (var i = 0; i < this.length; i++) { fn(this[i], i, this) }}
var arr = [1, 2, 3, 4, 5]
arr.myForEach(function (item, index, array) { console.log(item, index, array)})真正的forEach方法使用:
var arr = [1, 2, 3, 4, 5]arr.forEach(function (item, index, array) { if (item > 2) { console.log(item, index, array) }})我们用同样的方式来实现一下数组的find方法:
var arr = [1, 2, 3, 4, 5]
Array.prototype.myFind = function (fn) { for (var i = 0; i < this.length; i++) { var isMatch = fn(this[i]) if (isMatch) { res = this[i] return res } } return undefined}
arr.myFind(function (item) { return item > 2})findIndex方法h3
findIndex方法用法和find一样,只是返回的是索引,而不是元素本身。返回第一个匹配到的元素索引,如果遍历完没有匹配到则返回-1。
var arr = [1, 2, 3, 4, 5]
var res = arr.findIndex((item) => item > 2)console.log(res) // 2
Array.prototype.myFindIndex = function (fn) { for (var i = 0; i < this.length; i++) { var isMatch = fn(this[i]) if (isMatch) { return i } } return -1}
var indices = arr.myFindIndex(function (item) { return item > 2})console.log(indices) // 2sort方法h3
sort方法会改变原数组,返回排序后的数组。
var arr = [1, 5, 3, 2, 4]arr.sort() // 默认升序console.log(arr) // [1, 2, 3, 4, 5]arr.sort(function (item1, item2) { if (item1 > item2) { return -1 // 不交换 } else { return 1 // 交换 }})
console.log(arr) // [5, 4, 3, 2, 1]
// arr.sort(function(item1, item2) {// return item2 - item1;// });
// console.log(arr) // [5, 4, 3, 2, 1]当然也可以使用最基本的冒泡排序写一个自己的排序方法,特别注意传入mySort的回调函数fn,如果fn(item1,item2)<0,那么a会被排在b前面,如果fn(item1,item2)>0,那么a会被排在b后面,否则a和b的相对位置不变。
Array.prototype.mySort = function (fn) { for (var i = 0; i < this.length; i++) { for (var j = 0; j < this.length - i - 1; j++) { if (fn(this[j], this[j + 1])) { var temp = this[j] this[j] = this[j + 1] this[j + 1] = temp } } }
return this}
var sorted_array = arr.mySort(function (item1, item2) { return item1 > item2})
console.log(sorted_array)reduce函数h3
用来迭代数组,返回一个结果。
var arr = [1, 5, 3, 2, 4]// 初始化值:第一次执行的时候,对应的pre,我们设置为0var result = arr.reduce(function (pre, cur) { return pre + cur}, 0)
console.log(result) // 15如果没有赋值初始化值,则默认pre为数组的第一个元素。
arr.reduce(function (pre, cur) { console.log('pre:', pre, 'cur:', cur) return pre + cur})
// pre: 1 cur: 5// pre: 6 cur: 3// pre: 9 cur: 2// pre: 11 cur: 4但是需要注意,如果数组元素是对象,比如下列情况,因为没有传入初始化值,pre默认取数组第一项,是一个Object。回调函数内部的逻辑返回的是一个 Number,这就导致在第二次迭代时,pre从Object变成了Number。代码逻辑是按Object编写的(试图访问.price),当应用于Number类型的pre时,属性访问返回undefined,最终导致计算结果为NaN。
var products = [ { name: 'iphone', price: 1699, count: 3 }, { name: 'ipad', price: 999, count: 2 }, { name: 'macbook', price: 23999, count: 1 }, { name: 'airpods', price: 399, count: 5 }, { name: 'watch', price: 699, count: 2 },]
var totalPrice = products.reduce(function (pre, cur) { console.log('pre:', pre.price, 'cur:', cur.price) return pre.price * pre.count + cur.price * cur.count})
// pre: 1699 cur: 999// pre: undefined cur: 23999// pre: undefined cur: 399// pre: undefined cur: 699// NaN小结练习h3
给你一个nums数组,过滤所有的偶数,映射所有偶数的平方,并且计算它们的和
var nums = [11, 20, 50, 100, 88, 32]
var result = nums .filter(function (item) { return item % 2 === 0 }) .map(function (item) { return item * item }) .reduce(function (pre, cur) { return pre + cur }, 0)
console.log(result)DOM 操作h2
DOM相当于是js和html、css之间的桥梁,通过浏览器提供给我们的DOM API,我们可以对元素以及其中的任何内容做任何事情
DOM相关的API非常多,我们从如下顺序来学习:
- DOM元素之间的关系
- 获取DOM元素
- DOM节点的type、tag、content
- DOM节点的attributes、properties
- DOM节点的创建、插入、克隆、删除
- DOM节点的样式、类
- DOM元素/window的大小、滚动、坐标
DOM元素之间的关系h3

DOM中有很多元素,可以称之为节点,有注释节点、文本节点、元素节点等等。
元素节点从HTMLElement节点开始,又可以有HTMLLIElement、HTMLTextElement、HTMLDivElement等等
引入es6的类与继承简便方便写法之后,高屋建瓴,更好地理解这其实就是继承的关系,因为有些元素它们具有共同的属性,比如tagName、className等等,那么我们就可以将这些属性定义在父类中,而子类继承这些属性。再比如说,顶部的EventTarget中有addEventListener方法,那么所有的子类都继承这个方法。
节点之间 导航h3
Document节点表示的是整个载入的网页,它的实例是全局的document对象:
- 对DOM操作的所有操作都是从document对象开始的
- 它是DOM的入口点,可以从document开始去访问任何节点元素
<!DOCTYPE html><html> <head> <meta charset="utf-8" /> <title>DOM拿元素</title> </head> <body> not bad bro <div class="box">哈哈哈哈</div> <ul> <li>1</li> <li>2</li> <li>3</li> <li>4</li> <li>5</li> </ul>
<script> //基础方法 var bodyElem = document.body console.log(bodyElem.childNodes) // NodeList(6) [text, div.box, text, ul, text, script] // 获取body的第一个子节点 var firstChildOfBody = bodyElem.childNodes[0] console.log(firstChildOfBody) // not bad bro // 或者 var firstChildOfBody = bodyElem.firstChild console.log(firstChildOfBody) // not bad bro // 获取最后一个子节点 var lastChildOfBody = bodyElem.lastChild console.log(lastChildOfBody) // <script>标签中间包裹的代码 // 获取隔壁的节点 var nextSibling = firstChildOfBody.nextSibling console.log(nextSibling) // <div class="box">哈哈哈哈</div> // 获取隔壁的节点 var previousSibling = nextSibling.previousSibling console.log(previousSibling) // not bad bro // 获取body的父节点 var parentNode = bodyElem.parentNode console.log(parentNode) // <html>标签中间包裹的代码 </script> </body></html>元素之间 导航h3
现在我们不只想从body里拿子节点,而是想拿子元素,因为有些比如文本不属于元素,就要用
// 拿子元素,而不仅仅是子节点console.log(bodyElem.children) // HTMLCollection(3) [div.box, ul, script]
// 获取第一个子元素console.log(bodyElem.firstElementChild) // <div class="box">哈哈哈哈</div>// 相当于console.log(bodyElem.children[0]) // <div class="box">哈哈哈哈</div>// 以此类推...从上述例子能感受到Element继承自Node,Node继承自EventTarget
而Document也是继承自Node,所以Element和Document都是Node的子类,就是teacher和student的关系
Tabel 导航h3
- 表格基本结构标签:
<tabel>、<caption> - 表格分区标签:
<thead>、<tfoot>、<tbody> - 表格行与列标签:
<tr>、<th>、<td> - 表格布局相关标签:
<col>、<colgroup>
<table> <caption> 2025年报表 </caption> <colgroup> <col style="width: 100px" /> <col style="width: 100px" /> </colgroup>
<thead> <tr> <th>月份</th> <th>收入</th> </tr> </thead>
<tbody> <tr> <td>1月</td> <td>1000</td> </tr> <tr> <td>2月</td> <td>2000</td> </tr> <tr> <td>3月</td> <td>3000</td> </tr> </tbody>
<tfoot> <tr> <td>总计</td> <td>6000</td> </tr> </tfoot></table>跟着敲一遍,我们能清晰发现:
<colgroup>包含<col>标签<thead>包含<tr>、<th>标签<tbody>包含<tr>、<td>标签<tfoot>包含<tr>、<td>或者<th>标签<tr>包含<td>或者<th>标签
<!DOCTYPE html>
<html><head><meta charset="utf-8"><style> table{ border-collapse: collapse; } td{ border: 1px solid #000; padding: 8px 12px; }</style></head><body> <table>
<tbody> <tr> <td>1-1</td> <td>2-1</td> <td>3-1</td> <td>4-1</td> </tr> <tr> <td>1-2</td> <td>2-2</td> <td>3-2</td> <td>4-2</td> </tr> <tr> <td>1-3</td> <td>2-3</td> <td>3-3</td> <td>4-3</td> </tr> <tr> <td>1-4</td> <td>2-4</td> <td>3-4</td> <td>4-4</td> </tr> </tbody> </table>
<script> var tableElem = document.body.children[0]; // console.log(tableElem); // <table>...</table> for(var i=0;i<tableElem.rows[0].cells.length;i++){ tableElem.rows[i].cells[i].style.backgroundColor = 'red'; } </script></body></head></html>Form 导航h3
<body> <form action=""> <input name="account" type="text" /> <input name="password" type="password" /> <input name="hobbies" type="checkbox" checked /> <select name="fruits"> <option value="apple">苹果</option> <option value="banana">香蕉</option> </select> </form>
<script> var formElem = document.body.firstElementChild var inputElems = formElem.children console.log(inputElems) // HTMLCollection(4) console.log(formElem.elements) // HTMLFormControlsCollection(4) console.log(inputElems[0]) // <input name="account" type="text"> console.log(formElem.elements[0]) // <input name="account" type="text">
// 或者 var formElem = document.forms[0] // 获取第一个表单 var inputElems = formElem.children console.log(inputElems) // HTMLCollection(4) console.log(formElem.elements) // HTMLFormControlsCollection(4) console.log(inputElems[0]) // <input name="account" type="text"> console.log(formElem.elements[0]) // <input name="account" type="text"> </script></body>上述代码formElem.children是获取表单的直接子元素,是标准的DOM属性,返回HTMLCollection(类数组),包含所有子元素,包括非表单控件,比如说div、span等非表单元素
而formElem.elements是获取表单的所有表单控件,返回HTMLFormControlsCollection(类数组),只包含表单控件(input、select、textarea、checkbox…),不包含非表单控件
注意,表单里面提供了一种name属性,如果对应的html代码里写了name属性,可以通过formElem.elements.名字获取对象
比如:
var formElem = document.forms[0]var inputElem1 = formElem.elements.accountconsole.log(inputElem1) // <input name="account" type="text">拿到这个对象有什么用呢?我们可以通过.value属性拿到输入的值,比如:
window.addEventListener('click', function () { console.log(inputElem1.value)}) // 在account输入框输入一个值,点击一下,控制台就会打印出这个值通过类选择对应的元素h3
document.getElementsByClassName('类名'):返回包含所有该类元素的HTMLCollection集合document.querySelector('.类名'):返回第一个匹配的类元素(选择器查询)document.querySelectorAll('.类名'):返回所有匹配的元素组成的NodeList集合(选择器查询)
<!DOCTYPE html><html lang="en"> <head> <meta charset="UTF-8" /> <title>获取类选择器对应的元素</title> </head> <body> <div class="box"> <h2>Big title</h2> <div class="container"> <p> 我是段落,<span class="keyword">coderwhy</span>哈哈哈 <span class="keyword">coderwhy1</span> </p> </div> </div>
<script> // 我想把coderwhy这个单词变成红色 // 获取类选择器对应的元素 // 方法一:getElementsByClassName,返回一个类数组 var keywordCollection = document.getElementsByClassName('keyword') keywordCollection[0].style.color = 'red' // 方法二:querySelector,把遇到的第一个匹配的元素返回 var firstKeyword = document.querySelector('.keyword') firstKeyword.style.color = 'red' // 方法三:querySelectorAll,返回一个类数组 var keywordNodeList = document.querySelectorAll('.keyword') keywordNodeList[0].style.color = 'red' </script> </body></html>通过id选择对应的元素h3
document.getElementById('id'):返回id对应的元素document.querySelector('#id'):返回第一个匹配的id元素(选择器查询)
<div id="box">我是唯一的ID元素</div><!-- <div id="box">我是唯一的ID元素</div> --><script> // 方法1:getElementById(推荐,性能最好) var box1 = document.getElementById('box') console.log(box1) // <div id="box">...</div>(单个元素) console.log(box1.textContent) // 我是唯一的ID元素
// 方法2:querySelector(通用选择器) var box2 = document.querySelector('#box') console.log(box2 === box1) // true(同一个元素)</script>注意:浏览器在处理“多个元素共用同一个 id”这种非法场景时,会返回文档中第一个出现的 id 为 box 的元素(也就是第一个 <div id="box">),不会识别第二个。
id本来就是唯一的,所以后来有了class,class可以重复
通过标签选择对应的元素h3
document.getElementsByTagName('标签名'):返回包含所有该标签名的元素HTMLCollection集合document.querySelector('标签名'):返回第一个匹配的标签元素(选择器查询)document.querySelectorAll('标签名'):返回所有匹配的元素组成的NodeList集合(选择器查询)
<p>第一个段落</p><p>第二个段落</p><script> // 方法1:getElementsByTagName(动态集合) var pList1 = document.getElementsByTagName('p') console.log(pList1) // HTMLCollection(2) [p, p](集合) console.log(pList1[0]) // <p>第一个段落</p>(取第一个元素)
// 方法2:querySelectorAll(静态集合) var pList2 = document.querySelectorAll('p') console.log(pList2) // NodeList(2) [p, p](集合) console.log(pList2[0]) // <p>第一个段落</p>(取第一个元素)
// 方法3:querySelector(仅取第一个匹配的元素) var firstP = document.querySelector('p') console.log(firstP) // <p>第一个段落</p>(取第一个元素) console.log(firstP.textContent) // 第一个段落</script>通过名字选择对应的元素h3
document.getElementsByName('name'):返回包含所有该name属性的元素 HTMLCollection 集合
<input name="username" /><input name="username" /><script> var inputList = document.getElementsByName('username') console.log(inputList) // HTMLCollection(2) [input, input](集合) console.log(inputList[0]) // <input name="username">(取第一个元素)</script>实时性h3
是指DOM集合是否会随页面元素的变化而自动同步更新,对应DOM中动态集合的特性:
当某个方法标记为实时的时,它返回的元素集合是动态关联DOM的,如果页面中更新了匹配的元素,这个集合会自动更新内容(不需要重新调用方法);反之则是静态集合,一旦获取后就固定不变,DOM变化不会影响集合内容。
实时的:比如 getElementsByTagName、getElementsByClassName,它们返回的是 HTMLCollection 类型的动态集合。
// 1. 获取所有p标签(实时集合)const pList = document.getElementsByTagName('p')console.log(pList.length) // 假设初始是2
// 2. 页面新增一个p标签const newP = document.createElement('p')document.body.appendChild(newP)
// 3. 实时集合自动更新,长度变成3console.log(pList.length) // 3非实时的:比如 querySelectorAll
// 1. 获取所有p标签(静态集合)const pList = document.querySelectorAll('p')console.log(pList.length) // 假设初始是2
// 2. 添加一个p标签const newP = document.createElement('p')document.body.appendChild(newP)
// 3. 静态集合长度不变,还是2console.log(pList.length) // 2简单说,实时的就是集合和DOM绑定,DOM变则集合变;非实时的就是集合是DOM的快照,DOM变集合不变。
小结h3
当元素彼此靠近或相邻时,DOM导航属性(navigation property)非常有用,但是在实际开发中,我们希望可以任意获取某一个元素就需要
| 方法名 | 返回值类型 | 是否实时(动态集合) | 核心特性 | 典型示例 |
|---|---|---|---|---|
document.getElementById('id') | 单个Element(或null) | ❌ 无实时性(非集合) | 1. 基于ID哈希表优化,性能最优;2. ID需唯一,仅返回第一个匹配元素(非法重复ID场景);3. 无匹配返回null。 | const box = document.getElementById('box'); |
document.getElementsByClassName('类名') | HTMLCollection(类数组) | ✅ 实时 | 1. 动态集合,DOM增删改匹配元素时自动更新;2. 无匹配返回空集合;3. 不支持数组map等方法(需转数组)。 | const list = document.getElementsByClassName('keyword'); |
document.getElementsByTagName('标签名') | HTMLCollection(类数组) | ✅ 实时 | 1. 动态集合,DOM变化自动同步;2. 支持通配符*(匹配所有元素);3. 无匹配返回空集合。 | const pList = document.getElementsByTagName('p'); |
document.querySelector('选择器') | 单个Element(或null) | ❌ 无实时性(非集合) | 1. 支持复杂选择器(如#box .keyword);2. 仅返回第一个匹配元素;3. 无匹配返回null。 | const firstKeyword = document.querySelector('.keyword'); |
document.querySelectorAll('选择器') | NodeList(类数组) | ❌ 静态集合 | 1. 静态集合,DOM变化不更新(仅为获取时的DOM快照);2. 支持复杂选择器;3. 现代浏览器支持forEach;4. 无匹配返回空集合。 | const allKeyword = document.querySelectorAll('.keyword'); |
document.getElementsByName('name值') | NodeList(类数组) | ✅ 实时 | 1. 基于name属性匹配(常用于表单元素);2. 动态集合,DOM变化自动更新;3. 无匹配返回空集合。 | const inputList = document.getElementsByName('username'); |
关键补充说明
- “实时性”仅针对“集合类返回值”:单个Element(如
getElementById/querySelector)无“实时性”概念,因为返回的是固定元素引用(元素本身被删除则引用变为“空引用”); - HTMLCollection vs NodeList 核心差异:
HTMLCollection:仅由getElementsByXX系列返回,实时、无forEach(需转数组);NodeList:querySelectorAll返回的是静态NodeList(无实时性),getElementsByName返回的是动态NodeList(有实时性);现代浏览器中NodeList支持forEach,HTMLCollection不支持;
- 选型建议:
- 需实时监听DOM变化 → 用
getElementsByClassName/getElementsByTagName; - 一次性获取元素(无需同步DOM变化) → 用
querySelectorAll(语法更灵活); - 精准获取唯一元素 → 优先
getElementById(性能>querySelector('#id')); - 复杂选择器匹配 → 直接用
querySelector/querySelectorAll。
- 需实时监听DOM变化 → 用
节点Node常见的属性h2
nodeType属性,提供了一种获取节点类型的方法,它返回一个数值型的值
| 常量 | 值 | 描述 |
|---|---|---|
| ELEMENT_NODE | 1 | 元素Element节点,例如<div>、<p> |
| TEXT_NODE | 3 | 文本节点,Element或者Attr中实际的文字 |
| COMMENT_NODE | 8 | 注释Comment节点 |
| DOCUMENT_NODE | 9 | 文档Document节点,例如<html> |
| DOCUMENT_TYPE_NODE | 10 | 文档类型DocumentType节点,例如<!DOCTYPE html> |
nodeName属性,返回节点的名称,比如<div>的nodeName属性为"DIV"
tagName属性,返回节点的标签名,比如<div>的tagName属性为"DIV"
那么nodeName属性和tagName属性有什么区别呢?
- tagName属性仅适用于Element节点;
- nodeName是为任意Node定义的:
- 对于元素,他的意义与tagName相同,用哪一个都是可以的
- 对于其他类型节点(text、comment等),它拥有一个对应节点类型的字符串
<body> <!-- 我是注释 --> 我是文本 <div>我是div</div> <script> var bodyElement = document.body // 我现在想遍历body的所有子节点 for (var i = 0; i < bodyElement.childNodes.length; i++) { var node = bodyElement.childNodes[i] console.log(node.nodeName) console.log(node.nodeType) // 如果node是元素节点,则输出tagName if (node.nodeType === 1) { console.log(node.tagName) } } </script></body>data属性,针对非元素节点,获取数据
innerHTML属性,针对元素节点,获取元素内部的HTML内容
textContent属性,不管对于元素节点,对于文本节点,对于注释节点,获取数据,不包括标签
outerHTML属性,针对元素节点,获取包含元素的完整HTML内容
<body> <!-- 我是注释 --> 我是文本 <div> <span>我是span</span> </div> <script> var Node1 = document.body.childNodes[0] console.log(Node1.nodeName) // #text console.log(Node1.data) // console.log(Node1.textContent) // var Node2 = document.body.childNodes[1] console.log(Node2.nodeName) // #comment console.log(Node2.data) // 我是注释 console.log(Node2.textContent) // 我是注释 var Node3 = document.body.childNodes[2] console.log(Node3.nodeName) // #text console.log(Node3.data) // 我是文本 console.log(Node3.textContent) // 我是文本 var Node4 = document.body.childNodes[3] console.log(Node4.nodeName) // DIV console.log(Node4.data) // undefined console.log(Node4.innerHTML) // <span>我是span</span> console.log(Node4.outerHTML) // <div><span>我是span</span></div> console.log(Node4.textContent) // 我是span
Node4.innerHTML = '<h2>我是h2</h2>' console.log(Node4.innerHTML) // <h2>我是h2</h2> Node4.textContent = '<h2>我是h2</h2>' console.log(Node4.innerHTML) // <h2>我是h2</h2> </script></body>innerHTML设置为HTML字符串,会替换掉元素内部的所有内容,并把新的HTML字符串解析成DOM节点,并替换掉元素内部的所有内容。
textContent设置为字符串,会替换掉元素内部所有内容,并把新的字符串作为文本节点添加到元素内部,即使新的字符串中包含HTML标签,这些标签也不会被解析为DOM节点。
hidden属性,也是一个全局属性,可用于设置元素隐藏
<body> <div> <span hidden>我是隐藏的span</span> </div> <script> var spanElement = document.querySelector('span') console.log(spanElement.hidden) // true
setTimeout(function () { spanElement.hidden = false console.log('5秒后状态:', spanElement.hidden) }, 5000) // 5秒后显示 </script></body>value属性,针对表单元素比如说<input>、<textarea>、<select>(HTMLInputElement、HTMLTextAreaElement、HTMLSelectElement),获取表单的值
href属性,针对于链接元素<a>,<a href="...">(HTMLAnchorElement)获取链接的URL
src属性,针对图片元素<img>,获取图片的URL
id属性,所有元素(HTMLElement)的“id”特性(attribute)的值
attribute 分类h3
所以什么叫做属性?
<!-- 属性:attribute --><div id="app" class="box" title="riverwood" age="18" height="180"> <p class="text">hello world</p></div><a href="https://www.baidu.com">百度一下</a>这些都算是attribute,但是需要做一个区分
如果是HTML标准指定的attribute,称之为标准attribute
如果是自定义的attribute,称之为自定义attribute
attribute 操作h3
对于所有的attribute访问,都支持如下的方法:
elem.hasAttribute(name)检查特性是否存在elem.getAttribute(name)获取特性的值elem.setAttribute(name, value)设置特性的值elem.removeAttribute(name)删除特性elem.attributes获取所有特性,获得一个NamedNodeMap对象(可迭代)
<body> <!-- 属性:attribute --> <div id="app" class="box" title="riverwood" age="18" height="180"> <p class="text">hello world</p> </div> <a href="https://www.baidu.com">百度一下</a>
<script> var appElem = document.querySelector('#app')
console.log(appElem.attributes) // NamedNodeMap
for (var attr of appElem.attributes) { console.log(attr.name, attr.value) } // id app // class box // title riverwood // age 18 // height 180
console.log(appElem.attributes[0]) // id="app" console.log(appElem.hasAttribute('title')) // true console.log(appElem.getAttribute('title')) // riverwood appElem.setAttribute('title', 'hurstville') // 设置属性值 console.log(appElem.getAttribute('title')) // hurstville appElem.removeAttribute('title') // 删除属性 console.log(appElem.getAttribute('title')) // null </script></body>attribute具备的特征:
- 它们的名字是大小写不敏感的(id与ID相同)
- 它们的值总是字符串类型的
<body> <input type="checkbox" checked />
<script> var checkboxElem = document.querySelector('input') console.log(checkboxElem.getAttribute('checked')) </script></body>上述例子,checked属性的值是空字符串,而不是true,即使我们给checked属性赋值为true
<body> <input type="checkbox" checked="true" />
<script> var checkboxElem = document.querySelector('input') console.log(checkboxElem.getAttribute('checked'), typeof checkboxElem.getAttribute('checked')) // true string </script></body>虽然打印了true,但是是字符串,而不是布尔值,这时候就需要用到property了
propertyh2
元素中的属性称之为attribute,而对象中的属性称之为property
存在的意义是什么呢?我们先看下面的例子:
<body> <div id="abc" class="box" title="riverwood" age="18" height="180">我是box</div>
<script> var divElem = document.querySelector('.box') console.log(divElem.id) // abc console.log(divElem.name) // box console.log(divElem.title) // riverwood console.log(divElem.age) // undefined console.log(divElem.height) // undefined </script></body>这种调用方式正是js中对象调用属性的访问方式,这就是property,但是对于自定义的属性,js中没有对应的property
标准的attribute在对应的对象模型中都有对应的property
所以说,非标准的只能通过elem.getAttribute()访问,对于标准的attribute,会在DOM对象上创建与其对应的property属性
<body> <input type="checkbox" checked />
<script> var checkboxElem = document.querySelector('input') console.log(checkboxElem.checked) // true console.log(checkboxElem.getAttribute('checked')) // 空字符串 if (checkboxElem.getAttribute('checked')) { console.log('checkbox处于选中状态') // 虽然是选中状态,但是这里是不会打印的,因为空字符串 } // 就需要用property来判断了 if (checkboxElem.checked) { console.log('checkbox处于选中状态') // 这里会打印,因为property是true console.log(checkboxElem.checked, typeof checkboxElem.checked) // true boolean } </script></body>设置属性值h3
设置属性值,除了刚才说的setAttribute()方法外,还有elem.属性名 = value
虽然都是设置属性值,但其实不一样
具体内容详见property和attribute对比
data-* 自定义属性h2
刚刚聊完 Attribute 和 Property 的恩怨纠葛,现在正是切入 data-* 自定义属性的最佳时机。
为什么?因为在 HTML5 出现之前,开发者为了在 HTML 标签上“偷偷”存点数据(比如用户的 ID、商品的价格),经常会发明一些非标准的属性,比如 <div myId="1001">。这种做法虽然能用,但不规范,可能会和未来 HTML 标准冲突。
于是,HTML5 推出了 data-* 属性,给了我们一个官方认证的、合法的私有数据存放区。
基本规则h3
它的规则很简单:
- 必须以
data-开头。 - 后面可以接任何字符(不要有大写字母,建议用连字符 - 连接)。
例如:
<div id="user-card" data-id="12345" data-user-name="felix" data-role="admin" data-click-count="0">用户信息卡片</div>如何操作h3
如何在js中操作它?有两种流派:传统派和现代派
- 传统派:
getAttribute()和setAttribute()
因为data-*本质上就是HTML标签上的Attribute,所以完全可以用老派做法操作
var card = document.querySelector('#user-card')console.log(card.getAttribute('data-user-name')) // felixcard.setAttribute('data-role', 'programmer')优点:兼容性无敌(甚至支持 IE6)。 缺点:写起来字数多,而且拿到的永远是字符串。
- 现代派:
datasetAPI
HTML5为每个DOM元素提供了一个 dataset 属性。这是一个专门用来读写 data-*的对象(Map)。
注意:这里有一个非常重要的“驼峰命名”转换规则!HTML中的连字符命名(kebab-case)会自动转换成js中的驼峰命名(camelCase)。
- HTML, CSS: data-user-name
- JS: dataset.userName
var card = document.querySelector('#user-card')
// 1. 读取(自动去掉了 data- 前缀,并转为驼峰)console.log(card.dataset.id) // 12345console.log(card.dataset.userName) // felix
// 2. 修改(直接赋值,HTML 标签上会自动同步更新!)card.dataset.role = 'vip'// HTML 变成了 <div ... data-role="vip">
// 3. 新增card.dataset.newFeature = 'enabled'// HTML 增加了 data-new-feature="enabled"
// 4. 删除delete card.dataset.clickCount// HTML 上的 data-click-count 属性被移除实际案例:如下代码是一个用户信息卡片,点击按钮后,会更新用户信息。
<body> <div id="user-card" data-id="空号" data-name="匿名" data-age="未知"> 用户信息卡片: <span class="user-id"></span> <span class="user-name"></span> <span class="user-age"></span> </div>
<button id="btn-show-info">查看信息</button>
<script> var userCard = document.querySelector('#user-card')
var btnShowInfo = document.querySelector('#btn-show-info')
var userIdSpan = document.querySelector('.user-id') var userNameSpan = document.querySelector('.user-name') var userAgeSpan = document.querySelector('.user-age')
function updateUserInfo() { // var id = userCard.getAttribute('data-id') // var name = userCard.getAttribute('data-name') // var age = userCard.getAttribute('data-age') var { id, name, age } = userCard.dataset userIdSpan.textContent = id userNameSpan.textContent = name userAgeSpan.textContent = age }
updateUserInfo()
btnShowInfo.onclick = function () { // userCard.setAttribute('data-id', '123456') // userCard.setAttribute('data-name', '张三丰') // userCard.setAttribute('data-age', '18') userCard.dataset.id = '123456' userCard.dataset.name = '张三丰' userCard.dataset.age = '18'
updateUserInfo() } </script></body>进阶:CSS 也能读取 data-*,data-* 不仅仅是给js用的,CSS 也可以利用它来做样式控制,甚至提取内容。
/* 进阶:CSS 属性选择器 *//* 当 data-name 等于 "张三丰" 时,应用这个样式 */#user-card[data-name='张三丰'] { border: 2px solid gold; /* 金色边框 */}
#user-card::after { /* 黑魔法:直接读取 HTML 里的 data-id 属性值 */ content: 'ID: ' attr(data-id);
/* 简单的定位样式 */ position: absolute; top: 5px; right: 5px; font-size: 12px; color: #999; border: 1px solid #999; padding: 2px 5px; border-radius: 4px;}动态修改样式h2
我们现在想,点击一个按钮,让用户信息卡片变大,并且想让里面的字变成红色,可能会想到在点击事件里获取到对应位置的style上一个一个添加样式
<body> <div id="user-card" data-id="空号" data-name="匿名" data-age="未知"> 用户信息卡片: <span class="user-id"></span> <span class="user-name"></span> <span class="user-age"></span> </div>
<button id="btn-show-info">查看信息</button>
<script> var userCard = document.querySelector('#user-card')
var btnShowInfo = document.querySelector('#btn-show-info')
var userIdSpan = document.querySelector('.user-id') var userNameSpan = document.querySelector('.user-name') var userAgeSpan = document.querySelector('.user-age')
function updateUserInfo() { var { id, name, age } = userCard.dataset userIdSpan.textContent = id userNameSpan.textContent = name userAgeSpan.textContent = age }
updateUserInfo()
btnShowInfo.onclick = function () { userCard.dataset.id = '123456' userCard.dataset.name = '张三丰' userCard.dataset.age = '18'
updateUserInfo()
// 直接修改style // 变大 userCard.style.width = '400px' userCard.style.height = '200px' // 变色 userCard.style.color = 'red' } </script></body>但是这样做并不推荐,我们更推荐动态添加一个class,我们可以这样做
<head> <style> .active { width: 400px; height: 200px; color: red; } </style></head><body> <div id="user-card" data-id="空号" data-name="匿名" data-age="未知"> 用户信息卡片: <span class="user-id"></span> <span class="user-name"></span> <span class="user-age"></span> </div>
<button id="btn-show-info">查看信息</button>
<script> var userCard = document.querySelector('#user-card')
var btnShowInfo = document.querySelector('#btn-show-info')
var userIdSpan = document.querySelector('.user-id') var userNameSpan = document.querySelector('.user-name') var userAgeSpan = document.querySelector('.user-age')
function updateUserInfo() { var { id, name, age } = userCard.dataset userIdSpan.textContent = id userNameSpan.textContent = name userAgeSpan.textContent = age }
updateUserInfo()
btnShowInfo.onclick = function () { userCard.dataset.id = '123456' userCard.dataset.name = '张三丰' userCard.dataset.age = '18'
updateUserInfo()
// 覆盖原来的class,哎不对,原来似乎没有定义class userCard.className = 'active' } </script></body>不过如果这样操作,相当于如果一开始有一个class的话,就会把原来那个基础样式覆盖掉。
但我们可能更想既保留基础样式,又增加新增样式。
btnShowInfo.onclick = function () { userCard.dataset.id = '123456' userCard.dataset.name = '张三丰' userCard.dataset.age = '18'
updateUserInfo()
// 追加 而不是覆盖 userCard.classList.add('active')}除了elem.classList.add(class),还提供了一些其他该有的方法:
elem.classList.remove(class),移除一个类elem.classList.toggle(class),如果类不存在就添加类,存在就移除它elem.classList.contains(class),检查给定类,返回true/false
通过style属性操作内联样式,注意,对于多个单词组成的属性,请使用驼峰式
<body> <div class="box" style="background-color: aqua; color: white;">我是box</div>
<script> var boxElem = document.querySelector('.box') console.log(boxElem.style.backgroundColor) // 用驼峰命名法 </script></body>我们想拿到某个元素某一个样式,如果写在style属性中,肯定是能拿得到的
但是,如果某些样式并没有写在style属性中(非内联样式),比如
<head> <style> .box { font-size: 20px; } </style></head><body> <div class="box" style="background-color: aqua; color: white;">我是box</div>
<script> var boxElem = document.querySelector('.box') console.log(boxElem.style.backgroundColor) console.log(boxElem.style.fontSize) // 空字符串 </script></body>所以,要读取元素最终生效的样式(包括外部样式表和内联样式),必须使用全局方法 getComputedStyle(element)
该方法返回一个 CSSStyleDeclaration 对象,包含了所有已计算的样式。
比如,getComputedStyle(boxElem).fontSize 可以正确读取通过CSS类设置的字体大小。
<head> <style> .box { font-size: 20px; } </style></head><body> <div class="box" style="background-color: aqua; color: white;">我是box</div>
<script> var boxElem = document.querySelector('.box') console.log(getComputedStyle(boxElem).fontSize) console.log(getComputedStyle(boxElem).backgroundColor) </script></body>插入元素h2
node.append(...) —— 在节点末尾插入
在目标节点的内部最后位置添加内容(可以是节点/字符串)。
<body> <div>i feel so good</div> <script> // 比如我想再div末尾加一个p标签和文字 var div = document.querySelector('div') div.append( document.createElement('p'), // 创建一个p标签 '追加文字' // 插入字符串 )
console.log(div.outerHTML) // <div>i feel so good<p></p>追加文字</div> </script></body>node.prepend(...) —— 在节点开头插入
在目标节点的内部最前位置添加内容。
<body> <div>i feel so good</div> <script> // 比如我想在div开头加一个p标签和文字 var div = document.querySelector('div') div.prepend( document.createElement('p'), // 创建一个p标签 '追加文字' // 插入字符串 )
console.log(div.outerHTML) // <div><p></p>追加文字i feel so good</div> </script></body>node.before(...) —— 在节点前面(外部)插入
在目标节点的同级、且位于目标节点之前的位置添加内容。
<body> <div>i feel so good</div> <script> // 比如我想在div前面加一个p标签和文字 var div = document.querySelector('div') div.before( document.createElement('p'), // 创建一个p标签 '追加文字' // 插入字符串 ) </script></body>node.after(...) —— 在节点后面插入
在目标节点的同级、且位于目标节点之后的位置添加内容。
<body> <div>i feel so good</div> <script> // 比如我想在div后面加一个p标签和文字 var div = document.querySelector('div') div.after( document.createElement('p'), // 创建一个p标签 '追加文字' // 插入字符串 ) </script></body>node.replaceWith(...) —— 用新内容替换旧内容
用新内容替换目标节点。
<body> <div>i feel so good</div> <script> // 比如我想把div替换成p标签 var div = document.querySelector('div') div.replaceWith(document.createElement('p'), '追加文字') </script></body>node.remove() —— 删除节点
删除目标节点。
<body> <div> not bad bro <p>i feel so good</p> </div> <script> // 比如我想把div删除 var div = document.querySelector('div') var p = div.querySelector('p') p.remove() </script></body>这里div.querySelector('p')我们等于说是获取div下的第一个p标签,说明querySelector可以获取子元素下的
克隆元素h2
原节点.cloneNode(是否深克隆)
深克隆:复制原节点 + 它的所有子节点、属性、事件(但注意:js绑定的事件不会被克隆,只有html原生事件如onclick="xxx"会被克隆)
浅克隆:只复制原节点本身,不复制子节点(子节点会丢失)
小练习
页面初始结构:
- 有 1 个 “模板卡片”(包含标题、内容、“删除” 按钮);
- 有 1 个 “新增卡片” 按钮。
功能要求:
- 点击 “新增卡片”:克隆 “模板卡片”,并修改克隆卡片的标题为 “卡片 X”(X 是第几个新增的卡片,比如第 1 个新增是 “卡片 1”);
- 点击卡片内的 “删除” 按钮:删除当前卡片;
- 注意:模板卡片本身不能被删除(只删克隆出来的卡片)。
提示要点:
- 用cloneNode(true)深克隆模板卡片;
- 克隆后要修改卡片标题(比如通过querySelector找到标题元素改textContent);
- 给克隆卡片的 “删除” 按钮重新绑定点击事件(因为cloneNode不会克隆 JS 绑定的事件);
- 用计数器记录新增卡片的序号。
<body> <div class="card-container"> <div class="template-card"> <h2>card x</h2> <p class="content">this is content</p> <button class="delete-btn">delete button</button> </div> </div> <button class="add-card">add card</button>
<script> const addBtn = document.querySelector('.add-card') const templateCard = document.querySelector('.template-card') const cardContainer = document.querySelector('.card-container') let cardCount = 0
// 禁用模板删除按钮 templateCard.querySelector('.delete-btn').onclick = () => alert('模板不能删!')
// 新增卡片逻辑 addBtn.onclick = function () { cardCount++ // 序号从1开始 const newCard = templateCard.cloneNode(true) newCard.querySelector('h2').textContent = 'card' + cardCount cardContainer.append(newCard)
// 用立即执行函数绑定删除事件 ;(function (deleteCard) { newCard.querySelector('.delete-btn').onclick = function () { deleteCard.remove() // 删除当前卡片 } })(newCard) // 把当前克隆的newCard传给IIFE } </script></body>
Comments