
排序的依据h2
排序模型预估点击率、点赞率、收藏率、转发率等多种分数,融合这些预估分数(比如加权和),最后根据融合的分数做排序、截断
Share Bottom多目标模型h2
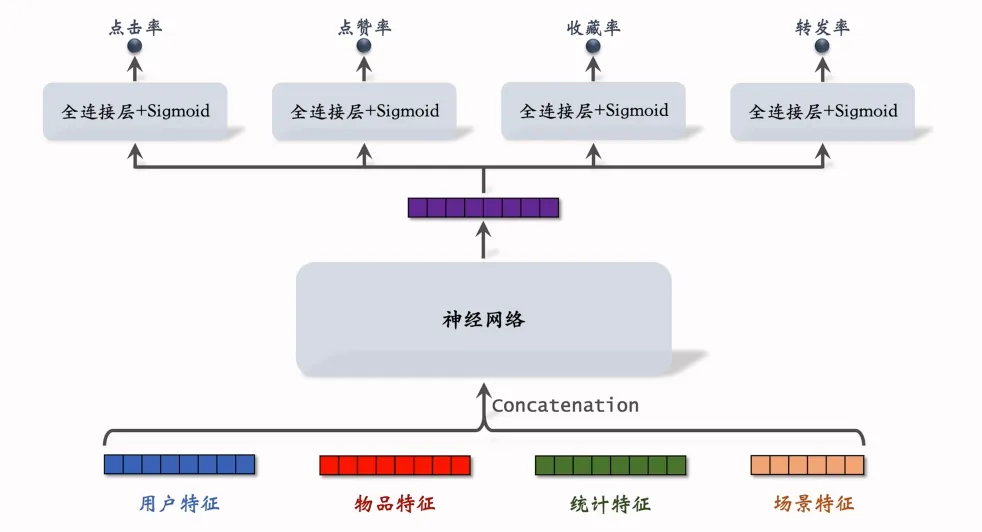
输入层:拼接四类特征,用户特征(如用户画像、历史行为)、物品特征(如内容类型、标签)、统计特征(如热门度、曝光量)、场景特征(如时间、地点)。
神经网络层:对拼接后的特征进行深层特征提取。
输出层:通过 4 个独立的 “全连接层 + Sigmoid 激活函数”,分别输出点击率、点赞率、收藏率、转发率的预测概率。
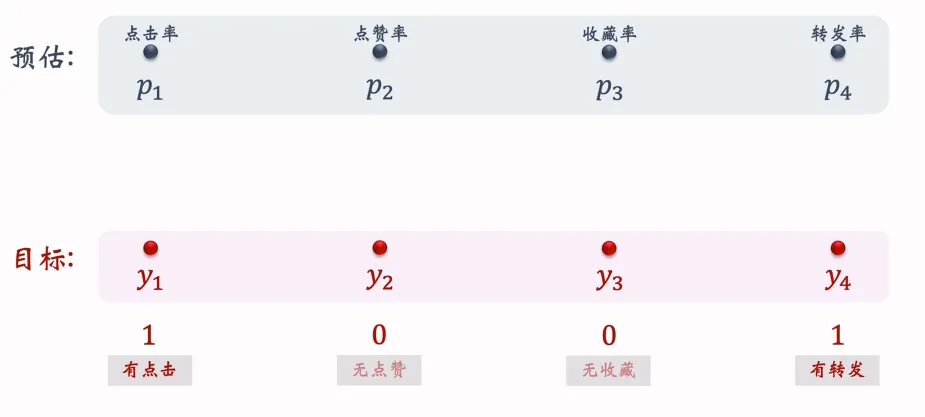
目标值是0、1,预测概率为0-1,实际上就是多个二元分类任务,既然如此损失函数就可以使用交叉熵。

我们把四个损失函数的加权和作为总的损失函数:
权重是根据经验设置的,在收集的历史数据上训练神经网络的参数,最小化损失函数,损失函数越小,说明模型预测的结果越接近于真实值,做训练的时候,对损失函数求梯度,做梯度下降更新参数
训练中存在的困难h2
类别不均衡,比如每100次曝光,约有10次点击,90次无点击,再比如每100次点击,约有10次收藏,90次无收藏
解决方案:负样本降采样,也就是保留一部分负样本,这样让正负样本数量平衡,也节约了计算
预估值校准h2
预估值需要校准之后才能用于排序,设正负样本数量分别为和(以点击为例,曝光后如果点击即为正样本,否则为负样本),负样本数量通常远大于正样本,在训练的时候,通常对负样本做降采样,抛弃一部分负样本。
使用个负样本,是采样率,由于负样本变少,预估的点击率大于真实点击率。
越小,负样本数越少,模型对点击率的高估就会越严重。
真实点击率:(期望)
预估点击率:(期望)
上述两式结合得到:
在线上做排序的时候,首先让模型预估点击率,然后用上述公式做校准,最后拿校准之后的点击率作为排序依据。
MMoEh2
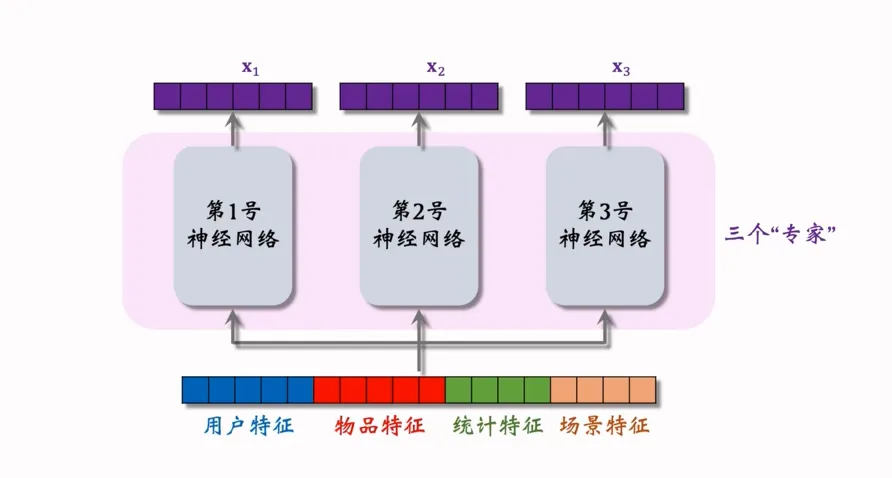
输入层:拼接用户特征、物品特征、统计特征、场景特征,覆盖了分析用户行为或内容推荐的核心维度。
专家层:3 个独立(不共享参数)的 “神经网络专家”(3只是一个超参数,通常会是4个或者8个),每个专家专注于学习特定子任务或特征模式(例如不同专家可分别擅长用户偏好分析、物品属性建模、场景适配性判断)。
输出层:每个专家输出对应的特征表示,为后续多任务预测或特征融合提供基础。
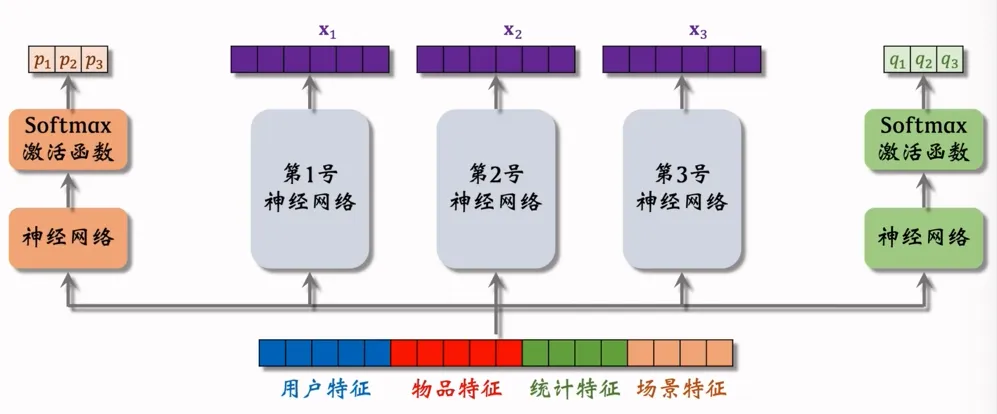
门控层:上图包含了2个门控网络,通过 “神经网络 + Softmax 激活函数” 输出专家权重和
上述2个门控网络代表着,最终会输出两种目标预估值,如下图
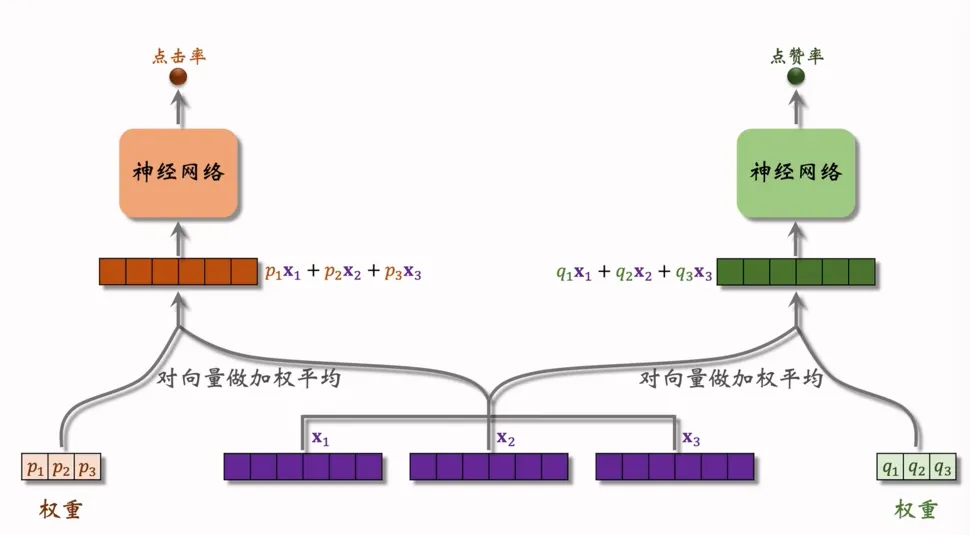
特征层:输入三个特征向量,,
权重融合层:对特征向量做加权平均,其中,,为点击率任务的特征权重,,,为点赞率任务的特征权重
任务输出层:两个独立的神经网络分别基于融合后的特征,输出 “点击率” 和 “点赞率” 的预测结果。
极化现象与解决办法h2
极化现象:Softmax输出值其中一个接近于1,其余接近0
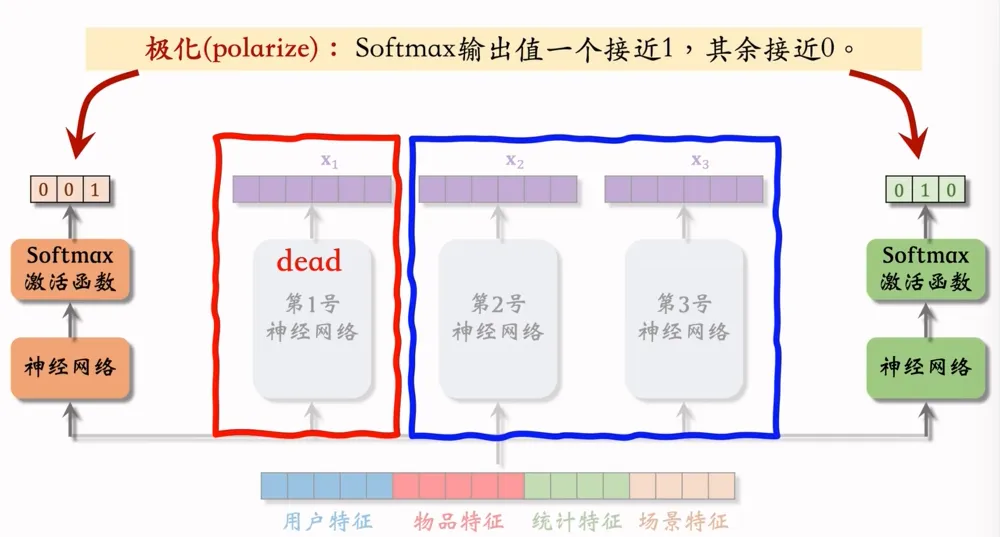
如上图,第1号专家神经网络没有被用到,那么MMoE退化成了一个简单的多目标模型,不会对专家做融合
解决办法:如果有n个专家,那么每个softmax的输入和输出都是n维向量,在训练时,对softmax的输出使用dropout。
为什么这样就能解决极化?
Softmax输出的n个数值被“临时屏蔽”的概率都是10%,这样每个专家被随机丢弃的概率都是10%,打破“权重只集中在少数专家”的局面。
预估分数融合h2
-
简单的加权和:
-
点击率乘以其他项的加权和:,其中,比如即曝光之后,点赞的概率
-
海外某短视频APP的融分公式:,其中,表示预估短视频的观看时长,是超参数,线上做A/B测试选出合适的超参数
-
国内某短视频APP的融分公式:根据预估时长,对n篇候选视频做排序,如果某段视频排名是第,则它得分,对点击、点赞、转发、评论等预估分数做类似处理,最终融合分数:
-
某电商的融分公式:电商的转化流程从曝光->点击->加购物车->付款,模型预估有,,,最终融合分数为
视频播放建模h2
与图文笔记排序的主要依据(点击、点赞、收藏、转发、评论)不同,视频播放建模的模型主要考虑的是视频的播放时长和完播,播放时长是一个连续性变量,可能会有人打算直接使用回归模型拟合播放时长,但其实这样做的效果不好!
播放时长h3
播放时长数据往往是“长尾分布”,即大部分视频被观看几秒,少数视频被观看数分钟甚至更久,且受比如“用户-视频-场景”这种多维度因素影响(比如用户习惯、视频类型、观看设备等),直接回归很难捕捉这种非线性、高维度的复杂关系。
YouTube 时长建模思路:以share bottom多目标为例,我们只关心最后一个全连接层的输出值,接着进入Sigmoid函数,输出是一个概率值,做训练,需要一个同样在0-1之间的目标值y(,其中为实际观测的播放时长,如果没有点击,则)来计算交叉熵损失
如果,那么,我们可以把作为播放时长的预估
完播率h3
-
回归方法:比如视频时长10分钟,实际播放了4分钟,那么实际播放率为,让预估播放率拟合y:,线上预估完播率,模型输出,意思是预计播放73%,和点赞率、收藏率、转发率、评论率一样,代表了用户对于物品的兴趣
-
二元分类方法:需要人为设定完播指标,比如完播80%,那么如果视频长度10分钟,播放大于8分钟作为正样本,播放小于8分钟作为负样本,做二元分类训练模型,线上预估完播率,模型输出,意思是正样本的概率为73%
注意h3
在实践中,我们不能直接把预估的完播率用到融分公式中,从直觉上来说,视频越长,完播率会越低,如果直接用完播率,则会对长视频不公平
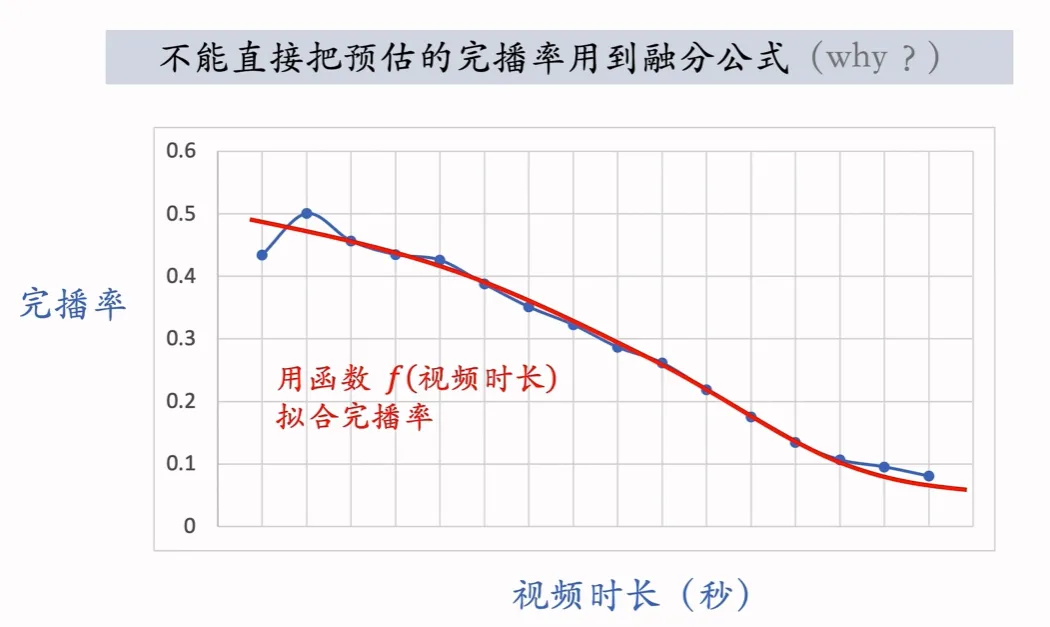
我们使用函数拟合完播率,我们要利用函数f对预估的完播率 做调整,这样可以公平对待长短视频的完播率
线上预估完播率 ,然后做调整
Comments